
Ensure the Quality of Web Services in the Age of Calm Computing
First published in JavaWorld, April 2001
Sal awakens: she smells coffee. A few minutes ago her alarm clock, alerted by her restless rolling before waking, had quietly asked, "Coffee?," and she had mumbled, "Yes." "Yes" and "no" are the only words it knows ...At breakfast Sal reads the news. She still prefers the paper form, as do most people. She spots an interesting quote from a columnist in the business section. She wipes her pen over the newspaper's name, date, section, and page number and then circles the quote. The pen sends a message to the paper, which transmits the quote to her office.
Once Sal arrives at work, the foreview (in her car) helps her to quickly find a parking spot. As she walks into the building the machines in her office prepare to log her in, but don't complete the sequence until she actually enters her office. On her way, she stops by the offices of four or five colleagues to exchange greetings and news. The telltale by the door that Sal programmed her first day on the job is blinking: fresh coffee. She heads for the coffee machine.
Coming back to her office, Sal picks up a tab and "waves" it to her friend Joe in the design group, with whom she is sharing a virtual office for a few weeks. They have a joint assignment on her latest project. Virtual office sharing can take many forms -- in this case, the two have given each other access to their location detectors and to each other's screen contents and location ... A blank tab on Sal's desk beeps, and displays the word "Joe" on it. She picks it up and gestures with it towards her liveboard. Joe wants to discuss a document with her, and now it shows up on the wall as she hears Joe's voice ...
Read the whole "Survival of the Fittest Jini Services" series:
- Part 1. Ensure the quality of Web services in the age of calm computing
- Part 2. Use transactions to coordinate the reliable interaction of Jini services
- Part 3. Implement transactional Jini services
Not your Father's Database
In the above words from a 1991 Scientific American article, "The Computer for the 21st Century," the late Mark Weiser, then head of Xerox's Palo Alto Research Center (PARC), shares his vision of a world in which computing technology quietly disappears into the background of everyday life, making itself unnoticeable, and yet indispensable. In the age of "calm computing," as Weiser described his vision, a person uses many computing devices, and these devices make information available ubiquitously, regardless of time or geographic location.
For most of us, the truly indispensable things in life become unnoticeable. We take for granted the telephone, the automobile, ATM machines, and lately email and the Internet -- and perhaps only notice them when they don't work as we expect.
However, while we take these tools of information processing and access for granted, we still can't do the same with the information itself. We would be looked upon with sharp eyes, should we, while traveling in our automobile, ask the car the name of the restaurant we enjoyed so much a few months before; or if, while at home, we ask our speaker system the current balance of our bank account. Currently, our activities are still focused around the tools of information access, and not around the information itself. The age of calm computing -- when the tools recede into the background, and we are free to interact with the information in a smooth, natural way -- has not yet arrived.
But this vision is well on its way.
Capturing and Storing Information
The notion of recording every piece of useful knowledge known to man has been a constant theme throughout history. The works of Aristotle or Plato are attempts at systematic and comprehensive description and categorization of all useful knowledge of their time. In the 18th century, Diderot and the other editors of the French Encyclopedia had a similar aim. Not surprising, the results span a great number of volumes. As with the Encyclopedia Britannica, no one expects to read such a work in its entirety. And, surely, these efforts had to limit themselves to the essential information, based on what the editors and writers considered useful at the time.
What we consider important today might not be so important in the future, and vice versa. The idea that we should record and make widely available every piece of information that can be captured first surfaced at the conclusion of World War II. At the time, scientists were pondering the fate of the large body of research produced in support of the war effort. Vannevar Bush, director of the Office of Scientific Research and Development, whose task it was to coordinate the work of all American scientists involved in wartime research, summarized the problem in his article "As We May Think," published in the July 1945 issue of the Atlantic Monthly:
The summation of human experience is being expanded at a prodigious rate, and the means we use for threading through the consequent maze to the momentarily important item is the same as was used in the days of square-rigged ships.
Bush suggests that scientific knowledge, or for that matter any knowledge, is only as valuable as it is shared with others. Therefore, devices should be constructed to record all scientific information.
One can now picture a future investigator in his laboratory. His hands are free, and he is not anchored. As he moves about and observes, he photographs and comments. Time is automatically recorded to tie the two records together. If he goes into the field, he may be connected by radio to his recorder. As he ponders over his notes in the evening, he again talks his comments into the record.
Thereafter, that information will be available through a special type of tool, which every person might possess:
Consider a future device for individual use, which is a sort of mechanized private file and library. It needs a name, and, to coin one at random, "memex" will do. A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.
As you probably recognize, the closest thing to "memex" is the Web. The Web is the universal information appliance, and thus, the most likely conduit to supply the large amounts of data needed to enable a "calm," unintrusive computing environment.
According to some estimates, the Web has been growing about tenfold each year. As I'm writing this, the Google search engine indicates that it knows about 1,346,966,000 Webpages. Assume that, on average, a Webpage contains 30 KB of information. Then, Google has access to something like 40 terabytes of data (or about 2.5 times the information stored in the Library of Congress in text format). Two years from now, it will likely be a gateway to more than four petabytes of information. (One terabyte is 1,000 gigabytes, and one petabyte is 1,000 terabytes.)
That's still not much, considering that already in 1999, about 300 petabytes worth of magnetic disk was sold. In "How Much Information Is There in the World?" Michael Lesk suggests that, if absolutely everything was recorded in digital media -- all the books, movies, music, conversations, as well as all human memory -- it would amount to a few thousand petabytes. Considering just the magnetic disks sold over the past few years, there already is enough storage to record everything.
Computer scientist David Gelernter, the inventor of space-based computing, which gave rise to technologies such as JavaSpaces, suggests that individuals and organizations start building their digital histories by saving every useful piece of information in a chronologically arranged "stream." Each item in the stream is fully indexed when it is added, and information can be organized on-the-fly into "substreams," based on content or on meta-information. As new information flows into the stream, it is automatically associated with the appropriate substreams. This idea already found its way into a commercial product, Scopeware. Figure 1 shows a browser-based window into a time-based stream via Scopeware's graphical user interface.
|
Figure 1: Graphical user interface of Scopeware |
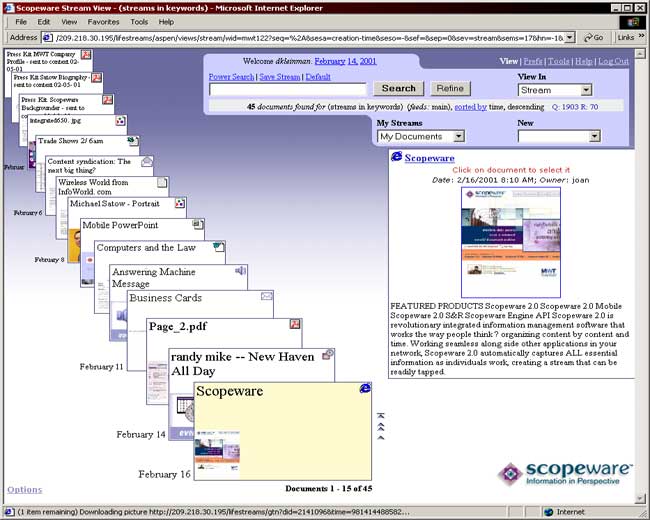
As organizations and individuals start building their digital "trails" over time, they will likely start relying on the availability of the digitally recorded information. But this information will be so vast that humans won't be able to directly use large portions of it.
This is fundamentally different from the categorization, or indexing, of Webpages. Web search engines, such as Google, aim to categorize the Web based on keywords or categories. But when the results of a search return a list of URLs, we click on those links to peruse the contents of those Webpages. Currently, those creating Webpages still have humans primarily in mind as their audience.
With the possibility of storing everything becoming a reality, the overwhelming portions of the information digitized and made available on the network will not be aimed for human consumption. At any rate, so much information will be available that we would have to either ignore very large portions of it, or utilize tools that let us interact with more of it. The latter implies that the information will be ubiquitously available to these tools, that the tools themselves will be readily available to us, and that they will operate calmly, in the background, to our advantage.
Therefore the adoption and widespread use of service-oriented software architectures, such as Jini, will be fueled, not by marketing hype, or any one company's market dominance, but by the need to access the vast amounts of information on the Web, most of which only machines can process.
Network Darwinism
Consider a travel reservation system. In this scenario every airline exposes its flight information on the Web in the form of objects, which are available for remote method calls. Such Flight objects are active, in the sense that they are ready to service remote method-call requests. Each object might reside inside a database management system, which in turn might distribute them among geographically dispersed nodes. In addition, airlines might expose objects that provide summary information on flights, such as the list of all flights between two cities. Other types of travel businesses provide objects that represent rental cars, hotel rooms, or credit cards.
You can construct other services to manipulate these objects to some business advantage. For instance, an airline reservation system might let a user book a flight, which is then charged on the customer's credit card. This service would obtain reference to the appropriate Flight object, perhaps via an airline's FlightSchedule service, and the CreditCard object representing the customer's credit card. Thereafter, it would make method calls to reserve a seat, charge the credit card, and then return a confirmation number to the customer. This scenario is illustrated in Figure 2.
|
Figure 2. Service composition |
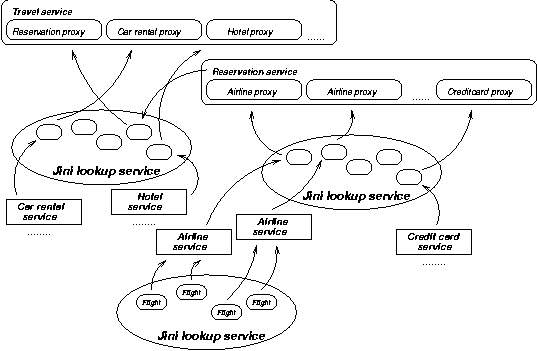
You can compose services of existing services. The reservation service, for instance, is composed of a Flight and a CreditCard service. Further, a travel agency service may be composed from the flight reservation service, and additional rental car and hotel reservation services. Service composition then results in an arbitrarily complex hierarchy, a "web" of services of services, or metaservices.
While the web of interdependent services mirrors the Web of interlinked Webpages, it also presents a fundamental difference. Humans, by and large, are tolerant of Web failures. We are all too familiar with "404 errors," "501 errors," or the occasional unavailability of a Website. However, we can somehow navigate around an error by, for instance, reloading a Webpage or visiting an alternate Website. Also, our memory of such errors is limited to short periods of time. (Can you recall all the nonworking links you clicked on in the last month?)
Machines (software services) are less resilient to error, and also have better memory of errors than humans. If a travel agency service relies on a flight reservation system, and the latter behaves erratically, or doesn't respond, the travel agency service first must detect the problem, and then likely record that the particular flight service was not working. Given that on the web of services many competing service providers will offer services that are semantically interchangeable (meaning that they offer essentially similar benefits), metaservices will do their best to select only those constituent services that perform well. Because metaservices might also become part of other services, it is in the interest of every metaservice to offer the highest-quality service. This will lead to automatic elimination of error-prone services over time. Among competing services, only the fittest will be utilized. The rest will likely die out.
Guaranteed 'Quality of Service'
Jini's infrastructure is designed to actually encourage eliminating unreliable services. First, a service participates in the Jini federation based on a lease. The service's implementation must renew the lease periodically, or it will expire and no longer be advertised in lookup services. Even if a lease is kept current, a client might experience network or other communication problems with the service's implementation. A Jini client could eliminate such a service's proxy from its lookup cache. Further, it could record service implementations that often produce errors, and upon subsequent lookup, exclude them from future lookup requests.
On today's Web of HTML pages, dependability is, at best, an anecdotal property: People talk about Websites being more or less reliable, more or less fast in responding to requests, and more or less accurate in terms of the information they provide. We need to pin down dependability far better if we plan to truly depend on these ubiquitously available information systems.
Computer scientist Gerhard Weikum has studied the notions of dependability of Web-based information systems. He argues that a service-oriented Web will only start to evolve when services strive toward a guaranteed quality of service (QoS). (See Resources for a link to Weikum's online papers.) Such guarantees have both qualitative and quantitative dimensions.
Qualitative QoS means that the service produces results that are acceptable in some human context. For instance, using a flight reservation system should mean that an airline seat is reserved, a credit card is charged, and a confirmation is received. Just one or two of these actions (for instance, charging a credit card without reserving the seat) would not be acceptable from a business perspective.
Quantitative QoS implies that a service provides acceptable performance in some measurable dimension. For instance, a service that provides streaming video must provide a certain number of frames per second to achieve smoothness of the movie. Or, a reservation system must respond within a certain time period to a reservation request (a few hundred milliseconds).
A software service can verify quantitative QoS guarantees relatively easily: If our reservation system does not respond within the specified time frame, a client service can conclude that it is not meeting its QoS guarantees. Other issues pending, the client could then look for another service that performs better.
The Rio project has already proposed a QoS notion for Jini services. QoS in Rio is based on Jini services having a set of requirements to properly execute in a runtime environment (such as bandwidth, memory, or disk requirements), and a runtime environment having a well-defined set of capabilities (such as available memory, disk space, bandwidth, and so forth). Rio strives to provide the best possible execution guarantees to a Jini service by matching a service's requirements with an environment's capabilities.
The notion of specifying a software service's requirements can be extended with a stochastic scale of (quantitative) service quality under a given environment's capabilities. For instance, a streaming video service could specify that it can deliver X number of frames per second, given a network bandwidth of N. A client could obtain this information from a service's service item, which could provide Entry objects for this purpose. These numbers would still only be approximate, but it would help clients locate services that match a required QoS level.
Many service qualities are not so easy to measure. Quality, at any rate, is often in the eyes of the beholder. It is helpful at this point to establish some terminology, some of which Weikum also describes as important for Web-based information services.
Qualities of a Service
Reliability is the guarantee that a service won't break within a given period of time in a way that the user (human or another service) notices the failure. For instance, if you reserve an airline seat, but no record of your reservation exists when you arrive at the airport, you know that the system is not reliable.
The trick is to make highly reliable systems out of unreliable components. John von Neumann, author of The Computer and the Brain, was the first to study this problem in the 1940s (see Resources); in his time, computer parts were notoriously flaky. In his work on the logical theory of automata, von Neumann strove to account for the probability of failure in a complex system. He presented a method to apply probabilistic logic to describe partial failure as an integral part of a system. He created a mathematical model for the human brain with a failure probability of once in 60 years. To achieve this level of reliability, he required 20,000 times redundancy: when a part failed, there had to be about 20,000 spares. Nowadays, disk mirroring, RAID, or redundant network connections are common ways to build a reliable system out of unreliable parts.
Jini is the first system for distributed computing designed with the explicit acknowledgement that each component of a distributed system, including the network, is unreliable. Because it squarely faces this issue up front, it is the first successful infrastructure to build Internet-wide reliable systems out of unreliable components.
Availability means that the system is up and running. Periodically, every system fails, resulting in downtime. When that happens, a system needs repair so that it can work again. How often a system fails is measured by the mean time between failure (MTBF). Modern hardware has incredibly high MTBF. Disk-drive maker Western Digital, for instance, specifies 300,000 hours of MTBF: "If a disk drive is operated 24 hours a day, 365 days a year, it would take an average of 34 years before this disk drive will fail." (See "What Is Mean Time Between Failure (MTBF)?").
A fun exercise is to find out the MTBF of equipment in your office or house (your TV set, refrigerator, or car). Then compare those figures to the MTBF of the operating system on your personal computer -- when did you have to reboot your machine last? In the world of competing, service-oriented software on the Web, users (human and software alike) will likely demand that software service providers give guarantees similar to the one Western Digital offers.
Often a system's component might fail, but the system can mask the failure, thus increasing system-level MTBF. Sectors on magnetic media, for instance, often fail, but disk drives and drive controllers can mask that by remembering the failed sector and avoiding it in future write requests.
If you deploy a software service that relies on other services, as illustrated in Figure 2, you might consider a similar strategy: have a redundant set of component services, and, when one fails, mark it so that your service won't use it again for a while. This technique, of course, exacerbates the survival of only the fittest services, since the flaky ones will be universally avoided.
Suppose your service fails once a year -- has an MTBF of one year -- and it takes one hour to repair (has a mean time to repair (MTTR) of one hour). This means that your service will be unavailable for one hour every year. Availability is computed as: Availability = MTBF/MTBF + MTTR. Thus, your service's availability is about 99.988 percent (8,760 (hours in a year) / 8,760 + 1). If we count the number of 9s, then it has about a "four 9s availability."
Clearly, one way to increase availability is to reduce MTTR. A few years ago, I noticed that the new version of a popular operating system restarted much quicker than its predecessor did: If you must reboot, reboot quickly. Well, it's one way to increase availability ...
But a better way to increase availability is to have a replica of your service running on the network. When the primary version fails, client requests can fail over quickly to the replica. From the client's point of view, the failover is considered a repair (since it doesn't care which copy it uses, as long as the replicas behave identically). If your service fails over to a replica in one minute, for instance, you will have increased your availability to six 9s (525,600 / 525,601 ~ 99.9998 percent), or by two orders of magnitude. As a client, you should not wait too long to fail over to a replica, but should also not do it too quickly, lest you incur the failover overhead. It's yet another reason why services must provide some explicit guarantees, or guidelines, to clients about their promised availability. Of course, as a service provider, you must then fix the broken service, and make a replica available as soon as possible.
Integrity is the promise that the system will accurately capture, or facilitate, a business process or some aspect of the real world. A system's designer must explicitly ensure that this property holds true during the system's lifetime. For instance, an airline reservation system should capture all reservations for a flight -- it should never project an incomplete picture of this information, or allow the number of reservations to exceed the number of airplane seats.
I will not discuss security here in detail, but the notion of trusting a service becomes paramount if we want to see a worldwide object Web offering vast amounts of information. Clearly, the concepts of trust and security in this massive world of information and ubiquitous computing are far more complex than what exists today on the Web of HTML pages.
Ideally we would want to verify that our system is secure, maintains its integrity, and provides good availability and reliability. Verifiability of a service's behavior, however, is a tricky issue. In an enterprise MIS setting, or one in which we are in control of a software system's complete development, we can run tests that probe a system's salient properties. Because we know what the output should be, given an input, we can verify that the system behaves as we expect. But do we run these tests when vital parts of the system are operated by entities over which we have no control, or when pieces of the system are discovered only at runtime?
Verifiability is an important way to establish trust, and therefore, to facilitate a ubiquitous object Web. Jini has a big advantage in this area over other distributed object-interoperation techniques. Jini relies on programming interfaces defined in the Java language for object-to-object interactions. Such interfaces extend the notion of object-oriented encapsulation to the network. An object's public interface is essentially its contract with the rest of the world: It promises to do what its public methods advertise. This promise is formulated both in terms of programming language (Java), and by way of a semantic specification typically provided in a human language. Given these two sources of information, a system's designer can verify whether a service on the network actually performs as promised.
As a developer of Jini services, you must keep in mind that some operations might not be testable. Testing, in essence, means that we measure a system's state, S0, at time T0. We then take similar measurements after performing a set of operations, resulting in S1 at T1. The difference between S0 and S1 is DeltaS0_S1. We then compare our expected difference, based on our algorithms, Deltaexpected with DeltaS0_S1, and see whether the two are similar.
A problem results when we can't measure either S0 or S1. Imagine a service that charges our credit card a given amount for the purchase of a good (such as an airline ticket), via the method int confNum chargeCard(String cardNumber, float amount, Merchandise product). The service also has a method that lets us inquire about the current balance: float balance(String cardNumber). State S0 at time T0 produces a balance of $1,000. Then we charge an airline ticket worth $500. However, the chargeCard() method fails to return a confirmation number. At that point, we request the balance again at T1, and it results in the value of $1,000 again.
What went wrong here? At first, it seems that the purchase didn't go through, and we should therefore retry it. Or could it be that the confirmation number got lost while in transit on the network? Or perhaps, between T0 and T1, the credit card company deposited our payment check for $500?
One way to handle a situation like this is to make method calls idempotent: Calling a method call twice or more should have the same effect as calling it once. Thus, the client of the credit-charging service can retry the operation until it receives either a confirmation number or an exception. If the card has already been charged, no effect will take place; if it has not been charged, the operation will likely succeed on subsequent tries. So while the service is not really testable, at least it provides some integrity guarantees.
Qualities of a Process
Once we understand the requirements we can expect, and demand, from a service, we should ask the broader question of whether the service is helpful to us at all. Specifically, we expect that the service will provide some guarantees with regard to the processes we are trying to accomplish with it. This question is similar to what an employer might ask about an employee: Given that an employee is reliable and highly available (shows up every day), has integrity, and can easily be checked in terms of work accuracy, is this person helpful to the company's business objectives? Is the employee supporting the organization's processes?
Process-centric notions of QoS take precisely this viewpoint. Specifically, we want to ensure that nothing bad happens by using the service, and that something good eventually happens. In computing terminology, we strive for safety and liveness. (See Leslie Lamport's "Proving the Correctness of Multiprocess Programs".) While these requirements sound simplistic, their implementation in actual information systems is not trivial.
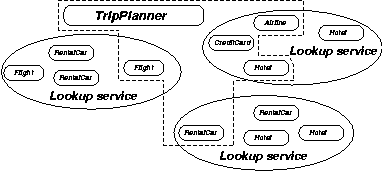
A classic trip-planning problem will illustrate the challenges. Suppose you wish to travel from Los Angeles to Salzburg, Austria. The trip will involve a flight from Los Angeles to Frankfurt, and then one from Frankfurt to Salzburg. Once there, you will drive a rental car to your hotel. And, of course, you will need to ensure that you have a hotel room at your destination. Further, you have a $1,500 travel budget. In addition, you would like to benefit from your frequent flyer club memberships with three different airlines. This scenario is illustrated in Figure 3.
|
Figure 3: Trip planning workflow with services |
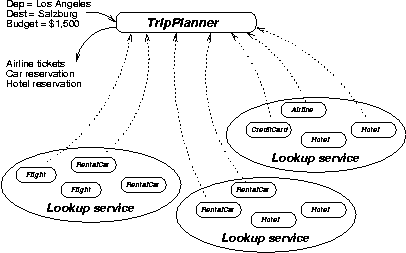
Flights, hotel rooms, and rental cars are all exposed on the network as services. Metaservices, such as flight, hotel, and rental car reservation systems, and credit card processors are also exposed. We must ensure that the interaction of these services produces some expected benefit (or at the least does not cause damage). An individual service, therefore, must guarantee that it is composable with other services in a meaningful way. This is very important, because the combination of services that produces the biggest benefit (such as saving the most money and providing the most convenient travel schedule) is the winner.
This problem has been studied in workflow systems, and now we will utilize similar techniques on the service-oriented object Web. Clearly, having just one leg of the trip completed is not sufficient; after all, you want to get to your destination. The service must also take into account your budget and frequent flyer memberships. In addition, because the object Web offers vast amounts of information, the best service (or "metaservice") will likely use more types of information. For instance, it may find that, based on your previous trips, you are eligible for a free hotel room in Frankfurt, and that staying there one night would reduce your airfare significantly. Looking at your previous correspondences/contacts, it might also discover that your uncle, who lives in Frankfurt, happens to have an evening open on his calendar, and that your favorite restaurant there is still taking reservations for dinner. Then you have the option of staying in Frankfurt for the night and having dinner with your uncle while also saving money. It is precisely this sort of service-to-service interaction that makes calm computing such an enticing vision.
Over the past few years, transaction-processing concepts were expanded to facilitate this sort of workflow or service composition. Two particular conceptual extensions are of interest here: complex or nested transactions, and transaction logic. The former takes each step of trip planning and fires off small transactions with each service involved. These small transactions are nested inside the big transaction, which is the trip planning. Transaction logic provides a way to specify conditions that must be met during a transaction's execution, and the possibility of a transaction to branch out into different execution paths, given different conditions.
Transactions are often explained with a banking example, using an ATM. When you withdraw $100 from an ATM, you expect that both your account balance will be reduced, and that the machine will eject the cash; that withdrawal is an atomic operation. The transaction should also not muddle your bank account, for instance, if the cash machine breaks down during the operation, a transaction should leave behind consistent results. If your wife withdraws cash from the same account at a different location, you probably don't want these two transactions to interfere. If your bank account has a balance of $100, then your bank would want to ensure that the two transactions are isolated; the system actually executes these tasks one after the other so that you both can't withdraw $100 simultaneously. Finally, you might want your transaction results to be saved persistently so that they are available after your transaction completes. The guarantees of atomicity, consistency, isolation, and durability, or ACID for short, are the distinguishing guarantees that transactions provide in a computation.
Transaction-oriented computing considers transactions to be the primary units of computation in a distributed system. According to transaction-processing pioneer Jim Gray, without transactions, you cannot dependably automate processes in distributed systems (see Resources).
In the travel-planning example, you could consider the trip a transaction, a process having ACID guarantees. Each step in the planning would then be a subtransaction. The services involved in every step are then transaction participants. Note that a transaction participant might, in turn, have nested transactions (that consist of other participants) -- for instance, legacy systems at an airline, or an object representing a rental car. This is illustrated in Figure 4.
|
Figure 4: Nested transactions |
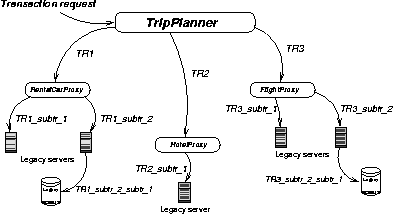
In addition to ACID guarantees, we also care about other guarantees in the trip-planning example: our trip must be within budget, and must take us to our destination. If we consider the transaction to be a computational entity -- an object, for instance -- then we can "push" the responsibility of ensuring these constraints inside the transaction. Because more than one good solution might satisfy your goals, the system should let the user select the most appropriate one. But it must also ensure that options don't become invalid while the user ponders the choice (because someone else in the meantime reserved that last airline seat, for example).
Imagine then a system where planning your trip would involve creating many transactions, evaluating the outcome of each, then letting you select the most desired outcome, and finally reversing the effects of the undesired transactions. That way, the outcome of this selection offers ACID guarantees, and ensures that you'll get the best possible trip, no "bad" outcomes will occur (going over the budget), and that the process terminates in a state acceptable to you (all tickets reserved and paid for). How to specify this sort of logic is beyond the scope of this article, but you might want to check out some references on advanced transaction models and transaction logic in Resources.
Spheres of Control
I'd like to conclude this article by revisiting an idea originally suggested in the late 1970s by two IBM researchers, Charles T. Davies and Larry Bjork. Extending their revolutionary idea might provide a unifying metaphor for the issues of dependability guarantees of Web-based object services.
In this scenario, when you request the planning of a trip from the system -- interfacing it via any user interface that the service provides, be it voice, a computer, and so forth -- the trip-planning service will locate all the component services needed to accomplish this objective, and bring them under a sphere of control. A sphere of control (SoC), thus, is a logical grouping of services on the network, which share a similar set of guarantees. This is illustrated in Figure 5.
|
Figure 5: Dynamic spheres of control |
To quote from Davies' paper, "Data Processing Spheres of Control" (IBM Systems Journal, 1978):
The kinds of control considered, for which there are potentially many instances, are process atomicity, process commitment, controlled dependence, resource allocation, in-process recovery, post-process recovery, system recovery, intraprocess auditing, interprocess auditing, and consistency.... Spheres of control exist for other purposes ... examples are privacy control, transaction control, and version control for both data and procedures.
At the outset of a new SoC, services agree upon this common set of guarantees, and then interact inside this control regime. A sphere of control, therefore, would be a "contract," which services deployed by organizations or individuals could use when interacting with one another on the object Web. An SoC would have both quantitative and qualitative guarantees for each participant service, and for the SoC as a whole. SoCs, therefore, would become a unit of trust and execution on the object Web.
An SoC would be represented as an object, which is saved persistently, even after the lifetime of the process it facilitates. The advantages of its persistence are evident when we consider either auditing or reversing a process. In the latter case, suppose your trip planning was done via an SoC, and you needed to cancel your trip. Since your process used many services, you'd need to instruct each one to reverse its original action. Why not delegate this job to your SoC object representing the trip reservation? Since it has the information of what steps were taken, which services were used, and what agreements were made between each service, it could arrange a reverse action with each service.
All your SoC objects would be available on the Web (for your own use only), and you could perform auditing and action reversal from virtually anywhere. With this in place, you could ask your car to find the restaurant you liked so much a few months before: your car would provide an interface, possibly via voice, to a space where all your SoC objects are accessible. A service could find the SoC objects that have restaurant services as participants, some of which you might have marked at the time as being excellent (using your PDA). It could then read a few attributes, such as the restaurant's name, from these back to you via the car's speaker system. You could then instruct your car to make a reservation at the desired restaurant, which it will do by creating a new SoC with the object representing the restaurant on the network. This is calm computing in action.
Conclusion
Services that can provide guarantees of dependability, both qualitative and quantitative, will have a better chance of survival in the coming age of calm computing. People have always relied on guarantees in their dealings with one another. The notion of law and the development of legal systems are in many ways attempts to establish sets of expectations people can rely on: when two people sign a contract, they explicitly promise certain guarantees to each other. If they fail to keep those guarantees, the contract will be annulled, and the faulty party will not be dealt with thenceforth. The state of the Web today is similar to societies without contract law: it is immensely useful, but its arbitrariness is becoming an obstacle to the development of more sophisticated forms of use required by a vision of ubiquitously available information. In the Jini community, we should start thinking seriously about how best to facilitate such guarantees for the services we develop.
Resources
- Read Frank Sommer's complete "Survival of the Fittest Jini Services" series:
- "The Coming Age of Calm Technology," Mark Weiser and John Seely Brown (Xerox PARC, October 5, 1996):
http://www.ubiq.com/hypertext/weiser/acmfuture2endnote.htm
- "The Computer for the 21st Century," Mark Weiser (Scientific American, September 1991):
http://www.ubiq.com/hypertext/weiser/SciAmDraft3.html
- "As We May Think," Vannevar Bush (Atlantic Monthly, July 1945):
http://www.theatlantic.com/unbound/flashbks/computer/bushf.htm
- "How Much Information Is There in the World?" Michael Lesk:
http://www.lesk.com/mlesk/ksg97/ksg.html
- Homepage of Gerhard Weikum, available papers:
http://www-dbs.cs.uni-sb.de/~weikum/home.htm
- Jim Gray's homepage:
http://www.research.microsoft.com/~gray
- For more information on John von Neumann's relevant work, see his article "Probabilistic Logic and the Synthesis of Reliable Organisation from Unreliable Parts." Collected Works, Vol. 5, A.H. Taub, Editor (Pergamon Press, 1961-1963). The article also appears in Automata Studies: Annals of Mathematics Studies, C.E. Shannon and J. McCarthy, Editors (Princeton University Press, 1956). He describes this issue also in "Principles of Large-Scale Computing Machines," Collected Works, Vol. 5, reprinted also in Annals of the History of Computing, Vol. 3, (Princeton University Press, July 1981). For a fascinating account of his work on the brain, see The Computer and the Brain, John von Neumann, et al. (Yale University Press, November 2000):
http://www.amazon.com/exec/obidos/ASIN/0300084730/javaworld
- "The Semantic Web," Tim Berners-Lee, James Hendler, Ora Lassila (Scientific American, 2001):
http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
- "The Rio Architecture Overview, Version 1.0" (Sun Microsystems):
http://www.sun.com/jini/whitepapers/rio_architecture_overview.pdf
- HP Laboratories' e-services projects have studied the notions of "exactly once" guarantees from e-services, as well as service composability:
http://www.hpl.hp.com/org/stl/emd/
- "Data Processing Spheres of Control," (IBM Systems Journal, 1978; vol. 17, issue 2; pp. 179-98). For a list of online articles from IBM Systems Journal, visit:
http://www.ibm.com/Search?v=10&lang=en&cc=us&q=IBM+Systems+Journal
- The Ninja project at Berkeley aims to define a highly robust infrastructure for Web services, using Java. At the core of Ninja is a cluster, which provides high availability and scalability for services:
http://ninja.cs.berkeley.edu/
- The Infospheres projects at CalTech explores the notion of objects representing services on the Web, and the idea of composable services:
http://www.infospheres.caltech.edu/
- David Gelernter's "The Second Coming -- A Manifesto," (The Third Culture):
http://www.edge.org/3rd_culture/gelernter/gelernter_index.html
- "What Is Mean Time Between Failure (MTBF)?" (Western Digital):
http://www.wdc.com/products/drives/drivers-ed/mtbf.html
MTBF FAQ: - D.H. Brown's availability research:
http://www.dhbrown.com/cffiles/RPPage.cfm?ID=202
- IEEE Distributed Systems Online on dependable systems:
http://www.computer.org/dsonline/dependable/
- For more information about streams-based computing and ScopeWare, visit the Mirror Worlds Website:
http://www.scopeware.com
- Jini FAQ and resources at Artima.com, maintained by Bill Venners:
http://www.artima.com
- "Proving the Correctness of Multiprocess Programs," Leslie Lamport (IEEE Transactions on Software Engineering, Volume 3, Issue 2, 1977) -- only the abstract is available online:
http://research.compaq.com/SRC/personal/lamport/pubs/pubs.html#proving
- Read past Jiniology columns:
http://www.javaworld.com/javaworld/topicalindex/jw-ti-jiniology.html
- The most comprehensive book on transactions processing (and, in general, on making distributed systems reliable) is Transaction Processing: Concepts and Techniques, Jim Gray and Andreas Reuter (Morgan Kaufmann, 1993):
http://www.mkp.com/books_catalog/catalog.asp?ISBN=1-55860-190-2
- Recent research into transactions has produced large and impressive literature. A good collection of essays on the subject is Database Transaction Models for Advanced Applications, Ahmed K. Elmagarmid (Morgan Kaufmann, 1992):
http://www.mkp.com/books_catalog/catalog.asp?ISBN=1-55860-214-3
- A collection of papers on transaction logic is available from Anthony Bonner's Website:
http://www.cs.toronto.edu/~bonner/papers.html#transaction-logic
- Sign up for the JavaWorld This Week free weekly email newsletter and keep up with what's new at JavaWorld:
http://www.idg.net/jw-subscribe
- Chat about all things Java in ITworld.com's Java Forum:
http://www.itworld.com/jump/jw-0413-jini/forums.itworld.com/webx?14@@.ee6b2b4
"Survival of the Fittest Jini Services, Part I" by Frank Sommers was originally published by JavaWorld (www.javaworld.com), copyright IDG, April 2001. Reprinted with permission.
http://www.javaworld.com/javaworld/jw-04-2001/jw-0413-jiniology.html
Talk back!
Have an opinion? Be the first to post a comment about this article.
About the author
Frank Sommers is founder and CEO of AutoSpaces.com, a startup focusing on bringing Jini technology to the automotive software market. He also serves as VP of technology at Nowcom, a Los Angeles-based outsourcing firm. He has been programming in Java since 1995, after attending the first public demonstration of the language on the Sun Microsystems campus in November of that year. His interests include parallel and distributed computing and the discovery and representation of knowledge in databases, as well as the philosophical foundations of computing. When not thinking about computers, he composes and plays piano, studies the symphonies of Gustav Mahler, or explores the writings of Aristotle and Ayn Rand. Frank would like to thank John McClain, member of Sun's Jini development team, for his valuable comments on this article.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)