Summary
It's great that Google is moving to Unicode 5.1 and that UTF-8 is so popular, but I wish they'd get their terms straight!
Advertisement
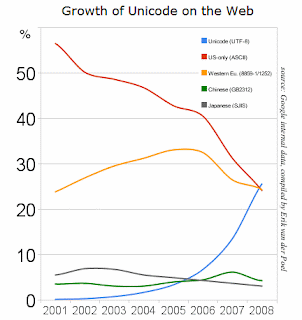
Today an article was posted to the Official Google Blog titled "Moving to Unicode 5.1". It describes how Google is adopting the latest revision of the Unicode standard, and how the UTF-8 encoding has recently surpassed both US-ASCII and Latin-1/Windows-1252 as the most popular encoding on the web. This is great news! And the graph is quite impressive.
The problem is that in the article, the term "Unicode" is being misused. Where they say "Unicode", they're really talking about the UTF-8 encoding. The first misuse is here:
Web pages can use a variety of different character encodings, like
ASCII, Latin-1, or Windows 1252, or Unicode.
Unicode is not a character encoding. Unicode is an internal, abstract, runtime concept (like an "image" or an "integer"). Most text encodings are compatible with Unicode. UTF-8 is simply a one-to-one round-trippable ASCII-compatible encoding. The blog article conflates Unicode with UTF-8, but they're quite separate. It's like the difference between a generic "image" and the data making up a PNG file, or between an "integer" and the bytes that make up its representation. Conflating Unicode and UTF-8 just perpetuates confusion among those who don't fully understand Unicode, and annoys those who do.
The graph title is also wrong. It says "Growth of Unicode on the Web", but it should say "Growth of UTF-8 on the Web".
Increasing awareness of Unicode and UTF-8 is great, but I wish it wasn't done via misinformation.
I'm not sure your summary is quite right either. ASCII, ISO-8859-1, and other character sets/encodings can represent a limited number of letters. Unicode represents a much large set of letters (not exactly all letters, but close in some sense). UTF-8 is an encoding that represents unicode. UTF-16 is also an encoding that represents unicode, and I imagine they would include that in the count of unicode pages. ISO-8859-1 represents a character set that is a subset of unicode. I suppose it's not really an encoding, because the character set has a one-to-one correspondence to bytes. So they are slightly incorrect in their terminology in that respect. There is a translation from ISO-8859-1 to Unicode, which in Python is spelled iso_8859_bytes.decode('iso-8859-1'). But technically it's not an encoding of Unicode, it is the encoding of the ISO-8859-1 character set.
Of course all of this is a big pedantic. Go Unicode! UTF-8-4-Life!
Oh, and I forgot, it gets worse: the character encoding doesn't mean that a page is actually in that character set. You can have ASCII-safe HTML that has unicode using numeric entities. So maybe they are fully decoding the page, resolving entities, and then seeing if the characters used are ASCII-only, ISO-8859-1, some other character set, or Unicode. But even that's unlikely, as there's still a ton of UTF-8 pages that are ISO-8859-1 safe. So... there's a lot of ways to phrase this stuff.
What they said is hardly misinformation in my view. The new characters they talk about were indeed added to Unicode, not just to one particular encoding form like UTF-8. Isn't it entirely acceptable to say that the use of Unicode on the web has grown when the physical manifestation of that growth is one particular Unicode enocding form (UTF-8)?
> I'm not sure your summary is quite right either. ASCII, > ISO-8859-1, and other character sets/encodings can > represent a limited number of letters. Unicode represents > a much large set of letters (not exactly all > letters, but close in some sense). UTF-8 is an encoding > that represents unicode.
Yes, that's true. My point was that Unicode is not an encoding; UTF-8 is.
> UTF-16 is also an encoding that > represents unicode, and I imagine they would include that > in the count of unicode pages.
No, the legend of the graph is explicit: "Unicode (UTF-8)".
> ISO-8859-1 represents a > character set that is a subset of unicode.
Correct.
> I suppose it's > not really an encoding, because the character set has a > one-to-one correspondence to bytes.
Sure ISO-8859-1 (Latin-1) is a text encoding. Latin-1/ISO-8859-1 can't handle the full range of Unicode code points, but that doesn't mean it's not a text encoding.
The Latin-1 and ASCII character sets are defined with a one-to-one correspondence to the bytes of their encodings, which is convenient but limiting. It's a crutch, a convenient fiction, that ASCII-speakers must unlearn. The problem is that in the past, the "character set" and the "encoding" were one and the same thing. Unicode can be (somewhat inexactly) thought of as a "character set" without a fixed encoding; UTF-8 is one of many possible encodings.
> So they are slightly > incorrect in their terminology in that respect. There is > a translation from ISO-8859-1 to Unicode, which in Python > is spelled > iso_8859_bytes.decode('iso-8859-1'). But > technically it's not an encoding of Unicode, it is the > encoding of the ISO-8859-1 character set.
ISO-8859-1 cannot encode ALL of Unicode, but sure it is an encoding: unicode_text.encode('iso-8859-1'). Of course that will fail if unicode_text contains characters outside of ISO-8859-1. Errors can can be avoided with an error handler like unicode_text.encode('iso-8859-1', 'xmlcharrefreplace').
> Of course all of this is a big pedantic. Go Unicode! > UTF-8-4-Life!
I assure you, the president of the Unicode Consortium has a firm grasp on the difference between Unicode and UTF-8. And a growth in UTF-8 encoding is certainly a growth in Unicode-encoded files, since UTF-8 encoding is a Unicode encoding. Google freely uses both UTF-8 and UTF-16 internally, depending on various things (see the "Google at Unicode" presentation at macchiato.com).
Disclaimer: I work for Google, but not for Mark Davis, or in i18n at all.
> Most text > encodings are compatible with Unicode.
Not true. Most text encodings are NOT compatible with Unicode. ISO-2022-JP - a popular Japanese encoding - how is that "compatible with Unicode". It isn't. Shift-JIS? GB2312? GBK? No, no. no. Many European encodings and certainly most Hebrew and Arabic encodings are very much not compatible with Unicode in any way you might want to slice it that makes any sense at all.
So, don't get too high and mighty about "misinformation"! Unicode on the web is UTF-8 for all intents and purposes. Is anyone serving UTF-16 pages? No. UTF-32? No. For better or worse, UTF-8 and Unicode are *effectively* the same thing on the web. Period. That's why the chart is labeled the way it is.
That makes the original article all the stranger. I stand by my original statement and the main point, that the Google blog article conflates Unicode with UTF-8, as in:
"Web pages can use a variety of different character encodings, like ASCII, Latin-1, or Windows 1252, or Unicode."
ASCII, Latin-1 (ISO-8859-1), and Windows 1252 (cp1252) are all concrete encodings. Unicode is abstract; there are no files or web pages with an encoding of "Unicode" (not UTF-8 etc.). Please show me an example to prove me wrong.
> ASCII, Latin-1 (ISO-8859-1), and Windows 1252 (cp1252) are > all concrete encodings. Unicode is abstract; there are no > files or web pages with an encoding of "Unicode" (not UTF-8 > etc.). Please show me an example to prove me wrong.
By definition in the standard the abstract Unicode encoding is realized in files by three official encoding forms: UTF-8 (Unicode/UCS Transformation Format 8-bit), UTF-16 (Unicode/UCS Transformation Format 16-bit), and UTF-32 (Unicode/UCS Transformation Format 32-bit). There are 7 official encoding schemes: UTF-8 (Unicode/UCS Transformation Format 8-bit), UTF-16 (Unicode/UCS Transformation Format 16-bit), UTF-16BE (Unicode/UCS Transformation Format 16-bit Big-Endian), UTF-16LE (Unicode/UCS Transformation Format 16-bit, Little-Endian), UTF-32 (Unicode/UCS Transformation Format 32-bit), UTF-32BE (Unicode/UCS Transformation Format 32-bit Big-Endian), and UTF-32LE (Unicode/UCS Transformation Format Little-Endian).
Each of these schemas represents one of the the encoding forms and each of the encoding forms represents the Unicode encoding.
Referring to the highest and most abstract level of Unicode encoding is not conflating it with UTF-8, but referring to the highest level, which includes all lower levels. It is as though sales of apples rose 50% and someone referred to the increase of sales of fruit. That is not misinformation, only generalizing at a higher level.
You may claim that UTF-8 is not Unicode and you may claim that apples are not fruits. In both cases you would be wrong. The local buyers of apples are not even buying generic apples (which do not exist), but MacIntosh apples, Delicious Apples, Granny Smith apples, and so forth.
That the ariticle uses the less term Unicode rather than the more specific term UTF-8 to refer to the growth of UTF-8 on the web is not misinformation because UTF-8 is a transformation format of Unicode.
important as the difference between ‘encoding’ and ‘character set’ is, i would still allow Unicode to be called an ‘encoding’, at least in non-technical usage.
the blowfish cjkv book contains a pretty readable clarification of the relevant terms. being very precise, one can distinguish a ‘character set’, a ‘coded character set’, and an ‘encoding’. ex.: the tōyō kanji of japan, the "kanji for general use", are a character set, but not a *coded* character set—they got listed on a sheet of paper, and no codes were associated with them. ASCII is a coded character set on the one hand (a set of characters which are bijectively mapped to a set of integer numbers) and a description of how to map those numbers to bit patterns (which constitutes an encoding; the mapping rules of ASCII happen to be used for lots of purposes, but nothing except convention make them compulsory).
however, in less strict jargon, often the (1) gamut of characters / glyphs, the (2) mappings of those elements to numbers, and the (3) way chosen to express those numbers as bit patterns can all be referred to as an ‘encoding’. ‘this web page is encoded in unicode’ is merely a way to say that ‘this web page uses (part of) the unicode character set’.
in this sense, i find the blog post uses a pretty clear language and gets its point across. it *can* be annoying when people mix character sets and encodings, but for the purposes of this article the difference is negligible. as has been pointed out, to really appreciate the trends presented, one would have to know whether individual characters or announced encoding per page got counted (as has been said above, declaring one encoding for the page and then using numerical character entities in the text is one of the very few opportunities in real life that allows to mix two different encodings within a single document. i am not aware of any way to mix three encodings that is supported by software).
i would like to add that to me utf-8 does *not* strictly have *anything* to do with unicode—it is simply a rule that maps integer numbers to bit patterns. you can go and express JIS codepoints or arbitrary binary data in terms of utf-8, and python’s unichr(i).encode() does not complain about invalid (undefined) codepoints (of which there are a lot). of course, every browser will still assume it’s unicode rather than JIS-written-as-utf-8, but that doesn't change the principle.
{kind=link}