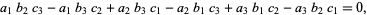This post originated from an RSS feed registered with Java Buzz
by Elliotte Rusty Harold.
Original Post: What is a Determinant?
Feed Title: The Cafes
Feed URL: http://cafe.elharo.com/feed/atom/?
Feed Description: Longer than a blog; shorter than a book
I was watching Gilbert Strang’s 18th lecture in 18.06 Linear Algebra a couple of days ago, and he laid out a theory of determinants that started from a few basic properties and derived all the usual results. However he provided essentially no motivation for what he was doing. Why these properties? How did any one ever think of these particular axioms? And more tellingly, what is a determinant, really? I don’t mean the official definition (here quoted from Wikipedia and similar to Strang’s):
If we write an n-by-n matrix in terms of its column vectors
where the aj are vectors of size n, then the determinant of A is defined so that
where b and c are scalars, v is any vector of size n and I is the identity matrix of size n. These properties state that the determinant is an alternating multilinear function of the columns, and they suffice to uniquely calculate the determinant of any square matrix. Provided the underlying scalars form a field (more generally, a commutative ring with unity), the definition below shows that such a function exists, and it can be shown to be unique.
I can follow the derivation from that, but it doesn’t really explain what a determinant is. And the only alternative I could find in Wikipedia or the readily available textbooks, was that it’s the volume of a parallelepiped of the matrix formed by the vectors representing the parallelepiped’s sides. Again, that feels like a derived property, not a true definition. However, Mathworld, did give me one big hint:
For example, eliminating x, y, and z from the equations = 0 = 0 = 0
gives the expression
which is called the determinant for this system of equation.
So here’s the answer: the determinant is the condition under which a set of linear equations has a non-trivial null space. Or,, more simply, the determinant is the condition on the coefficients a, b, c… of a set of n linear equations in n unknowns such that they can be solved for the right hand side (0, 0, 0, …0) where at least one of the unknowns (x, y, …) is not zero. Let me prove that:
To make things simpler, let’s start with the 2 by 2 case:
ax + by = 0
cx + dy = 0
Without loss of generality, assume that a != 0. (If it does we can just swap the two equations. And if a == c == 0, then the set of equations has only the trivial solution y == 0.)
Now eliminate x and y from these equations. From the first equation we get
x = -by / a
Substituting into the second we get
c (-by / a) + dy = 0
implies
(d – bc/a) y = 0
so either y = 0 (trivial solution) or, if y != 0, we have
d – bc/ a = 0
which implies
ad – bc = 0
the usual determinant formula for a 2 by 2 matrix. So what this says is that if ad – bc = 0, then given any y we can pick x = -by / a and the equations are solved. That is, we have non-zero solutions (an infinite number of them in fact) for
ax + by = 0
cx + dy = 0
In other words, the matrix A := [[a, b], [c, d]] has a non-trivial null space. In particular, it has a null space of at least rank 1. That means that:
The matrix A has a rank of at most 1. (This was shown a few lectures back in 18.06, and is sometimes called the rank-nullity theorem.)
The columns of A are linearly dependent.
All linear combinations of the columns of A take the form of a constant times either column.
In fact, these are three different ways of saying the exact same thing. (And for clarity on these points watch the first few lectures of 18.06.)
Continuing onward, the equation Ax = b can only be solved when b is a linear combination of the columns of A, but in this case, that’s just a line. We can easily pick a vector in the plane that is not a linear combination of the columns of A. Choose one such vector b’. For definiteness pick [a, 2c]. If an inverse existed then we could solve the equation Ax = b‘ as x = A-1b‘; but since we can’t solve that equation, no such inverse can exist. Thus when the determinant of A (a.k.a. det(A), a.k.a. ad – bc) == 0, the matrix A is not invertible. Q.E.D.
Anyway, that’s where the determinant comes from. And what is the determinant? It’s a condition on the coefficients of a set of n linear equations in n unknowns (represented by the square matrix A) such that the equation Ax = 0 has solutions other than the zero vector. From that all the rest follows. Or at least it does for the 2 by 2 case. I still need to extend this description to cover the n by n case. Nonetheless that is, to me at least, a much more satisfying and intuitive definition than a set of three unmotivated axioms that just happen to magically generate a host of inobvious properties.
P.S. If anyone knows a better way to include math in WordPress, please let me know.
The answer is in the third sentence of the Wikipedia piece:
"The determinant provides important information when the matrix is that of the coefficients of a system of linear equations, or when it corresponds to a linear transformation of a vector space: in the first case the system has a unique solution if and only if the determinant is nonzero, in the second case that same condition means that the transformation has an inverse operation."
It's used to test for the solvability of linear equations. Consider it the linear algebra equivalent of Divide by Zero.
OK, a different type of answer. If one asks, "why is the determinant these *particular* set of operations", the answer boils down to reverse engineering matrix inversion. In order to perform inversion, these set of operations must be true, and they're easier to calculate before setting off to solve with inversion. Not that I know how the determinant was first discovered to do this, of course.
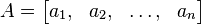



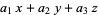 = 0
= 0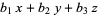 = 0
= 0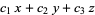 = 0
= 0