|
|
|
Sponsored Link •
|
Summary
It's great that Google is moving to Unicode 5.1 and that UTF-8 is so popular, but I wish they'd get their terms straight!
|
Advertisement
|
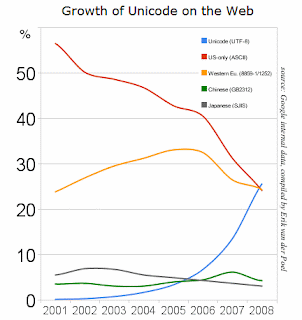
Today an article was posted to the Official Google Blog titled "Moving to Unicode 5.1". It describes how Google is adopting the latest revision of the Unicode standard, and how the UTF-8 encoding has recently surpassed both US-ASCII and Latin-1/Windows-1252 as the most popular encoding on the web. This is great news! And the graph is quite impressive.
The problem is that in the article, the term "Unicode" is being misused. Where they say "Unicode", they're really talking about the UTF-8 encoding. The first misuse is here:
Web pages can use a variety of different character encodings, like ASCII, Latin-1, or Windows 1252, or Unicode.
Unicode is not a character encoding. Unicode is an internal, abstract, runtime concept (like an "image" or an "integer"). Most text encodings are compatible with Unicode. UTF-8 is simply a one-to-one round-trippable ASCII-compatible encoding. The blog article conflates Unicode with UTF-8, but they're quite separate. It's like the difference between a generic "image" and the data making up a PNG file, or between an "integer" and the bytes that make up its representation. Conflating Unicode and UTF-8 just perpetuates confusion among those who don't fully understand Unicode, and annoys those who do.
The graph title is also wrong. It says "Growth of Unicode on the Web", but it should say "Growth of UTF-8 on the Web".
Increasing awareness of Unicode and UTF-8 is great, but I wish it wasn't done via misinformation.
Have an opinion? Readers have already posted 11 comments about this weblog entry. Why not add yours?
If you'd like to be notified whenever David Goodger adds a new entry to his weblog, subscribe to his RSS feed.
| David Goodger has been using Python since 1998, and began working on reStructuredText and Docutils in 2000. A proud Canadian, he lived in Japan for 7 years, where a stint at a document processing company in Tokyo began his love/hate relationship with structured markup. David is a Python Enhancement Proposal (PEP) Editor and a member of the Python Software Foundation. He currently lives outside of Montreal, Quebec, with his Japanese wife and their two children. |
|
Sponsored Links
|
{kind=link}