
Build a Compute Server with JavaSpaces
First published in JavaWorld, January 2000
I've just returned from the second Jini Community Summit, where Ken Arnold and I led a birds-of-a-feather session on JavaSpaces. This encouraging meeting highlighted a number of interesting JavaSpaces applications, including Bill Olivier's JavaSpaces-based email system at the University of Wales. Also featured was the Department of Defense's explorations of battlefield management software, in which battlefield resources, such as tanks, are represented in a space.
In addition, there was significant interest in continuing to advance the JavaSpaces technology, and a number of areas were suggested for its improvement. One problem that the conference attendees wanted to confront was the painful process of setting up and running JavaSpaces (as well as Jini) for the first time -- probably the greatest barrier to using the technology. This problem is now being addressed in a new working group started by Ken Arnold, called Out of the Box (for more information, see the Resources section at the end of the article). Another area of community effort involves the development of helper or utility interfaces and classes that provide a valuable set of tools for new JavaSpaces developers. This article is based around one of those tools in particular: the compute server.
Basically, a compute server is an implementation of a powerful, all-purpose computing engine using a JavaSpace. Tasks are dropped into the space, picked up by processes, and then computed; the result is written back into the space and, at some point, retrieved. Beginning JavaSpaces programmers often ask how to implement such a system; in fact, the JavaSpaces Technology Kit ships with two sample compute servers, which perform computations for ray tracing and cryptography.
Compute servers are quite useful even for advanced programming. At the Jini Summit, it was decided that a common set of interfaces should be created to standardize JavaSpaces-based compute servers so that programmers could avoid reinventing the wheel every time they wanted to implement one. As a result, the community has created a working group whose goal is to build a specification and reference implementation of a compute-server architecture. One aim of this article is to kick off that work.
The Compute Server Explained
A compute server provides a service that accepts tasks, computes them, and returns results. The server itself is responsible for computing the results and managing the resources that complete the job. Behind the scenes, the service might use multiple CPUs or special-purpose hardware to compute the tasks more quickly than a single-CPU machine could.
Historically, compute servers have been used to take advantage of the resources of large farms of processors in order to tackle computationally intensive problems -- ray tracing, weather modeling, cryptography, and so-called "grand challenge" computational problems. More recently, compute servers have begun to move into the mainstream, and have been put to work in a variety of environments, from the creation of financial models for Wall Street to the construction of large-scale order-entry and fulfillment centers that service the Web. All of these applications use the compute server to break a large computational problem into smaller problems, and then allow a distributed set of processors to solve these smaller problems in parallel.
Compute servers come in two forms: special-purpose and general-purpose. The SETI@home project is a good example of a special-purpose compute server. SETI@home makes use of the idle cycles of common desktop PCs to search for artificial signals of extraterrestrial origin within radio telescope data. The SETI compute server (which is formed by a group of PC users who have agreed to run the SETI@home screensaver on their PCs) is considered a special-purpose server because it only performs one type of computation: it searches for messages from outer space.
General-purpose compute servers allow you to compute any task -- you can add new tasks at will, and the server automatically incorporates their corresponding code. This is a powerful idea. For example, a corporation might create a compute server out of all the idle machines on its network. Computationally intensive problems can then be run across this compute server, making use of unused resources on the network as they become available. This lets the corporation more effectively use its existing installed base of hardware, thus reducing its overall hardware requirements. While you could do this with a special-purpose compute server, the administrative costs would be a nightmare; every time a new application needed to be run, it would have to be installed across the entire organization. With a general-purpose server, this happens automatically.
Many space-based compute servers have been built over the years. While I was part of the Linda group at Yale University, we built several such systems. The most sophisticated of these was a system called Piranha, built by classmate David Kaminsky. Piranha adaptively configured itself to the available resources on the network; as the name suggests, CPUs began feeding on the tasks that needed to be worked on as they became available. All our attempts at building compute servers were a bit unsatisfying, however, because the tasks had to be statically compiled into the server, thus limiting it to special purposes. JavaSpaces vastly improves this situation by moving code between processes -- you can move code into the compute server any time you need a new task computed. This is exceedingly easy with JavaSpaces; in fact, the properties of the space (inherited from Jini and RMI) allow it to transparently import new code into the compute server for you.
Compute servers can be built quickly with just a few lines of code. However, creating a reliable and robust compute server is a challenge that requires knowledge of most JavaSpaces and Jini APIs. In this article, I will explore many of the subtle aspects of JavaSpaces programming. My goal is to develop a basic compute server that can compute arbitrary tasks. Along the way, you will get a better feel for some of the JavaSpaces APIs that Susanne and I described in our last article.
Compute Server Design
Let's start with a big picture of the compute server and its relation to JavaSpaces. The typical space-based compute server looks like the figure below. A master process generates a number of tasks and writes them into a space. When we say task in this context, we mean an entry that both describes the specifics of a task and contains methods that perform the necessary computations. One or more worker processes monitor the space; these workers take tasks as they become available, compute them, and then write their results back into the space. Results are entries that contain data from the computation's output. For instance, in a ray-tracing compute server, each task would contain the ray-tracing code along with a few parameters that tell the compute process which region of the ray-traced image to work on. The result entry would contain the bytes that make up the ray-traced region.
|
|
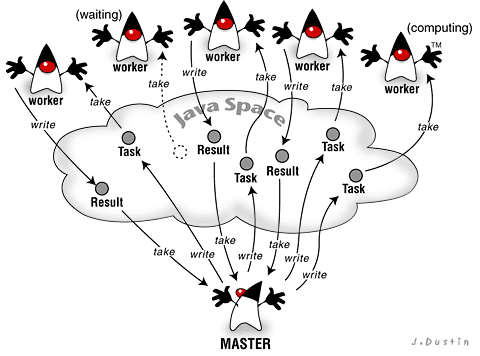
(Illustration by James P. Dustin, Dustin Design)
There are some nice properties the contribute to compute servers' ubiquity in space-based systems. First of all, they scale naturally; in general, the more worker processes there are, the faster tasks will be computed. You can add or remove workers at runtime, and the compute server will continue as long as there is at least one worker to compute tasks. Second, compute servers balance loads well -- if one worker is running on a slower CPU, it will compute its tasks more slowly and thus complete fewer tasks overall, while faster machines will have higher task throughput. This model avoids situations in which slow machines becoming overwhelmed while fast machines starve for work; instead, the load is balanced because the workers perform tasks when they can.
In addition, the masters and workers in this model are uncoupled; the workers don't have to know anything about the master or the specifics of the tasks -- they just grab tasks and compute them, returning the results to the space. Likewise, a given master doesn't need to worry about who computes its tasks or how, but just throws tasks into a space and waits. The space itself makes this very easy, as it provides a shared and persistent object store where objects can be looked up associatively (for more details on these aspects of spaces, please refer to November's column). In other words, the space allows a worker to simply request any task, and receive a task entry when one exists in the space. Similarly, the master can ask for the computational results of its (and only its) tasks -- without needing to know the specifics of where these results came from.
Finally, the space provides a feature that makes this all work seamlessly: the ability to ship around executable content in objects. This is feasible because Java (and Jini's underlying RMI transport) makes underlying class loading possible. How does this work? Basically, when a master (or any other process, for that matter) writes an object into a space, it is serialized and transferred to that space. The serialized form of the object includes a codebase, which identifies the place where the class that created the object resides. When a process (in this case, a worker) takes a serialized object from the space, it then downloads the object from the appropriate codebase, assuming that its JVM has not downloaded the class already. This is a very powerful feature, because it lets your applications ship around new behaviors and have those behaviors automatically installed in remote processes. This capability is a great improvement over previous space-based compute servers, which required you to precompile the task code into the workers.
Implementing the Compute Server
For masters and workers to exchange task objects, they must agree on a common interface for those objects. There aren't many requirements for the task object (at least in this simple implementation); all that is really needed is a method that instructs the task to start computing.
The well known Command pattern is used for this purpose. The interface for the Command pattern looks like this:
public interface Command {
public void execute();
}
This pattern, which consists of a single method (typically called execute), lets you decouple the object that invokes an operation from the object that can perform it. In this case, the object that will invoke the operation is a worker that has cycles to spare and time to compute a task. The object that knows how to perform the operation is the task itself. Different master processes are free to implement various execution methods, so that workers can perform a variety of computations for different masters. See Resources for pointers to information about Command and other patterns.
To make use of the Command interface in this compute server, you must augment it:
package javaworld.simplecompute;
import net.jini.core.entry.Entry;
public interface Command extends Entry {
public Entry execute();
}
Note that I've added extends Entry to the interface definition and imported the Entry class from the net.jini.core.entry package. You may recall from Part 1 of our series that, for an object to be written into a space, it must be instantiated from a class that implements the Entry interface. I've also changed the return type of the execute method to return an object of type Entry. This provides a way for computations to place results back into the space. We'll discover how this is done as we take our next step: implementing the worker.
The Worker
The worker is a straightforward concept: it continually looks for a task, takes it from the space, computes it, returns a result (if the task specifies that this is to be done), and then starts over. Here is the code:
package javaworld.simplecompute;
import jsbook.util.*;
import net.jini.core.entry.Entry;
import net.jini.core.lease.Lease;
import net.jini.space.JavaSpace;
public class Worker {
JavaSpace space;
public static void main(String[] args) {
Worker worker = new Worker();
worker.startWork();
}
public Worker() {
space = SpaceAccessor.getSpace();
}
public void startWork() {
TaskEntry template = new TaskEntry();
for (;;) {
try {
TaskEntry task = (TaskEntry)
space.take(template, null, Long.MAX_VALUE);
Entry result = task.execute();
if (result != null) {
space.write(result, null, 1000*60*10);
}
} catch (Exception e) {
System.out.println("Task cancelled");
}
}
}
}
I started by importing the Entry and Lease core Jini packages, along with the JavaSpace class. I also imported the utility package jsbook.util, from JavaSpaces Principles, Patterns, and Practice by Susanne Hupfer, Ken Arnold, and myself, which is freely available on the Web (see Resources). I will say more about this class shortly; it contains some utility methods with which you can access a space via Jini.
With the imports out of the way, let's step through the class definition. First, you define a static main method, which simply instantiates a new Worker and calls its startWork method. Before looking at this startWork method, lets first take a closer look at the Worker constructor. This constructor includes a call to SpaceAccessor.getSpace, which is supplied in the jsbook.util package. This method looks for a JavaSpace service on the local Jini network with the name JavaSpace, obtains a handle to the space, and then returns it as a result of the call. I am leaving out some of the behind-the-scenes details, but will return to them later in the series. (If you can't wait, you can find further details in JavaSpaces Principles, Patterns, and Practice.) For now, let's assume that, once this call has finished, you have a handle to a space.
Now let's go back to our startWork method. In this method, we first want to create a template to retrieve tasks from the space. However, there's a bit of a problem, since we must use an actual class as a template; we can't use interfaces (or abstract classes) as templates, so our Command interface cannot be used to retrieve tasks from the space. To remedy this, we need to create a base task class, which can, as the name implies, be used as the basis for all tasks. Here is such a class:
package javaworld.simplecompute;
import net.jini.core.entry.Entry;
public class TaskEntry implements Command {
public Entry execute() {
throw new RuntimeException(
"TaskEntry.execute() is not implemented.");
}
}
The TaskEntry implements the Command interface. Since TaskEntry can't be an abstract class (if it were, the worker wouldn't be able to instantiate it and use it as a template), we need to provide an implementation of the execute method. Rather than providing a concrete implementation that does nothing, we instead throw a runtime exception if this method is ever invoked. This encourages subclasses to implement this method, even though they have no compile-time requirement to do so.
Now that we have a TaskEntry, let's return to the startWork method. The method first instantiates a template from TaskEntry that can be used to retrieve any task written into the space. Recall from Part 1 of our series that a template can match an entry of the same type or subtype, so any subclasses of TaskEntry will match this template.
With a template in hand, we then enter a continual for loop. Within this loop, we call take on the space to retrieve a task entry, waiting as long as necessary for one to arrive. Once we've retrieved a task, we then call its execute method. If a nonnull result is returned, we then write it back into the space with a lease time of 10 minutes (this is expressed in the code as 1000*60*10 -- time here is measured in milliseconds). If the master takes longer than 10 minutes to retrieve the result, then it will be removed by the space in order to keep things tidy. After writing back the result, the worker then continues with the next task. If any exceptions occur along the way (if the space throws an exception on the take or write, say, or if the execute method throws an exception), then the task is ignored and the worker looks for the next task. This isn't the optimal way to handle these exceptions, since the task will be lost forever if it's not computed and thrown away. Susanne and I will fix this flaw in an upcoming article, using Jini's transactions.
Our compute server is now complete! This is the power of Jini and JavaSpaces: in only about 30 lines of code, we've implemented a complete compute server. I'd like to add some things, such as the transactions mentioned above, to improve some aspects of the server; but even at this early stage of development, we'll find that the space takes care of almost everything for us. It handles the communication between master and worker, the persistence of the task and result entries, and the automatic class loading. When we do add the transactions (a task that won't involve a lot of code), it will even handle the problem of partial failure.
Of course, the server isn't much good without a master to generate some tasks; so let's flesh out our project and develop one.
The Master
I am going to develop a simple master that generates two kinds of tasks: addition and multiplication tasks. In each case, the master initializes the tasks with two integers and then writes the task into a space. For addition tasks, the worker adds the two integers together and returns the result; likewise, for multiplication tasks, the two numbers are multiplied and then the results are written to the space. These tasks are overly simple and not particularly interesting in and of themselves, but will serve as a means of testing the compute server.
Let's start by defining the tasks. Here is the AddTask:
package javaworld.simplecompute;
import net.jini.core.entry.Entry;
public class AddTask extends TaskEntry {
public Integer a;
public Integer b;
public AddTask() {}
public AddTask(Integer a, Integer b) {
this.a = a;
this.b = b;
}
public Entry execute() {
Integer answer = new Integer(a.intValue() +
b.intValue());
AddResult result = new AddResult(a, b, answer);
return result;
}
}
Here, we first define two fields to hold the values that are to be added, a and b. Recall from Part 1 of our series that these fields must be objects and declared public if we want them to be useful in JavaSpaces applications. Next, we define two constructors: the no-arg constructor required by all entries, and a constructor that accepts the two integer values.
We then define the execute method, which simply adds the two integers together and then creates an AddResult object that is returned as a result of the method.
It should be obvious that defining the multiplication task will follow exactly the same pattern, except that the execute method will multiply the two values rather than adding them, and return a MultResult object rather than an AddResult object. You can see the definition of MultTask in MultTask.java (see Resources).
Now let's look at the AddResult and MultResult result entries, both of which are derived from a base class called ResultEntry. (We'll see why we've created this base class shortly.) Here is the definition of ResultEntry:
package javaworld.simplecompute;
import net.jini.core.entry.Entry;
public class ResultEntry implements Entry {
public Integer a;
public Integer b;
public Integer answer;
public ResultEntry() {}
}
The ResultEntry class defines three fields: the two integer inputs to the computation (called a and b), and an integer output (called answer). We also provide the mandatory no-arg constructor.
The AddResult entry is subclassed from ResultEntry, and looks like this:
package javaworld.simplecompute;
public class AddResult extends ResultEntry {
public AddResult() {}
public AddResult(Integer a, Integer b, Integer answer) {
this.a = a;
this.b = b;
this.answer = answer;
}
public String toString() {
return a + " plus " + b + " = " + answer;
}
}
This class provides two constructors and a toString method that prints the values of a, b, and the total value. As you might expect, the MultResult class is very similar to AddResult (you can find the definition for MultResult in Resources as well).
Now we can define the Master class:
package javaworld.simplecompute;
import jsbook.util.*;
import net.jini.core.entry.*;
import net.jini.core.lease.Lease;
import net.jini.space.JavaSpace;
public class Master {
private JavaSpace space;
public static void main(String[] args) {
Master master = new Master();
master.startComputing();
}
private void startComputing() {
space = SpaceAccessor.getSpace();
generateTasks();
collectResults();
}
private void generateTasks() {
for (int i = 0; i < 10; i++) {
writeTask(new AddTask(new Integer(i), new Integer(i)));
}
for (int i = 0; i < 10; i++) {
writeTask(new MultTask(new Integer(i), new Integer(i)));
}
}
private void collectResults() {
for (int i = 0; i < 20; i++) {
ResultEntry result = takeResult();
if (result != null) {
System.out.println(result);
}
}
}
private void writeTask(Command task) {
try {
space.write(task, null, Lease.FOREVER);
} catch (Exception e) {
e.printStackTrace();
}
}
protected ResultEntry takeResult() {
ResultEntry template = new ResultEntry();
try {
ResultEntry result = (ResultEntry)
space.take(template, null, Long.MAX_VALUE);
return result;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
The Master class is similar to the Worker class. You include the same imports and provide a static main class that creates an instance of the Master class, on which it calls the startComputing method. This method calls two of Master's methods: generateTasks and collectResults.
The generateTasks method writes 10 addition tasks and 10 multiplication tasks into the space for the workers to compute. It does this by performing two for loops from 0 to 9, calling writeTask to write a newly instantiated task entry into the space on each pass through the loop. In the first loop, an AddTask is written; a MultTask is written in the second. Both tasks are instantiated with the values (0,0), (1,1), and so on. The writeTask method simply writes the task into the space with an indefinite lease -- that is, the task will remain in the space as long as the space is running.
The collectResults method retrieves the results of these tasks from the space. It does this by iterating through the total number of tasks (in this case, 20) and calling the takeResult method. Once a result is returned from this method, it is printed, which results in its toString method being called. If the result is a AddResult, then we should get output that shows that addition took place; if it is MultResult, we should get output that shows the products of multiplication.
Let's quickly look at the takeResult method. This method first creates a template to match results. Note that it creates a ResultEntry, the superclass of both AddResult and MultResult. By doing this, the method can match any entry that subclasses the ResultEntry, and thus can match both of the result-entry types with which we are dealing here. The method then performs a take operation, waiting as long as necessary for a result entry to arrive in the space.
We now have the complete master code, with its associated tasks, so let's take it all out for a spin. With our Jini and JavaSpaces services running, we now run a couple instances of the worker and one instance of the master. We should see something like the following as output from the master:
0 plus 0 = 0
1 plus 1 = 2
2 plus 2 = 4
3 plus 3 = 6
4 plus 4 = 8
0 times 0 = 0
1 times 1 = 1
5 plus 5 = 10
2 times 2 = 4
3 times 3 = 9
4 times 4 = 16
5 times 5 = 25
6 times 6 = 36
7 times 7 = 49
8 times 8 = 64
9 times 9 = 81
6 plus 6 = 12
7 plus 7 = 14
8 plus 8 = 16
9 plus 9 = 18
Each task was computed and its result was returned in the result entry. Note that, because of the semantics of the take operation on the space, the tasks may be computed and returned in an arbitrary order. In general, this isn't a problem; in those cases in which it is, you can write more sophisticated code to enforce an ordering.
Summary
I've demonstrated a simple compute server in this article. With a small amount of code, we've implemented a server capable of executing arbitrary code on behalf of a master process. It would take some work to make this code ready for general use, and even more to create a compute server that is industrial strength and will soldier on in the face of partial failure. For instance, at this stage in our server's development, there is no method of distinguishing one master's tasks from another -- if we ran two concurrent instances of the master, then we'd most likely get mixed result sets returned by the collectResults method. We also have no way to handle exceptions in the task code when it is running within the worker's environment, or to handle the failure of workers when they are computing tasks. If either of these events occurred, the tasks being computed would be lost, which would lead to the master computing incorrectly. If the task to compute a piece of a ray-traced image was lost, for instance, then the image would never be completed.
Susanne and I will tackle many of these issues in remaining articles of this series, and in the compute-server working group at Jini.org. Please come and join us.
Resources
- The complete source code for this example:
http://www.javaworld.com/jw-01-2000/jini/code.zip
- The source code from the JavaSpaces book:
http://java.sun.com/docs/books/jini/javaspaces/JSBookExamples.zip
- The Compute Server Jini working group (requires free registration at Jini.org):
http://developer.jini.org/exchange/projects/computeserver/
- Ken Arnold's Out of the Box working group:
http://developer.jini.org/exchange/projects/outofbox/
- "The Nuts and Bolts of Compiling and Running JavaSpaces Programs," Susanne Hupfer:
http://developer.java.sun.com/developer/technicalArticles/Programming/javaspaces/index.html
- Read the whole "Make Room for JavaSpaces" series:
- Part 1. Ease the development of distributed apps with JavaSpaces:
http://www.artima.com/jini/jiniology/js1.html
- Part 2. Build a compute server with JavaSpaces:
http://www.artima.com/jini/jiniology/js2.html
- Part 3. Coordinate your Jini apps with JavaSpaces:
http://www.artima.com/jini/jiniology/js3.html
- Part 4. Explore Jini transactions with JavaSpaces:
http://www.artima.com/jini/jiniology/js4.html
- Part 5. Make your compute server robust and scalable:
http://www.artima.com/jini/jiniology/js5.html
- Part 6. Build and use distributed data structures in your JavaSpaces programs:
http://www.artima.com/jini/jiniology/js6.html
- Part 1. Ease the development of distributed apps with JavaSpaces:
- More information on the latest Jini Community Summit:
http://www.jini.org/NEWS/1026.communitymeeting2.html
- The definition of
MultTask:
http://www.javaworld.com/jw-01-2000/jini/MultTask.java
- The definition of
MultResult:
http://www.javaworld.com/jw-01-2000/jini/MultResult.java
- More on space models and compute servers:
http://www.cs.yale.edu/Linda/piranha.html
- Design Patterns: Elements of Reusable Object-Oriented Software, Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (Addison-Wesley, 1995) -- more information on design patterns:
http://www1.fatbrain.com/asp/bookinfo/bookinfo.asp?theisbn=0201633612&from=NCN454
- The official JavaSpaces users mailing list:
http://archives.java.sun.com/archives/javaspaces-users.html
- The Jini users mailing list also has a fair amount of JavaSpaces-related discussion:
http://archives.java.sun.com/archives/jini-users.html.
- For an exploration of space-based programming and an in-depth look at the JavaSpaces technology APIs, refer to JavaSpaces Principles, Patterns, and Practice by Eric Freeman, Susanne Hupfer, and Ken Arnold (Addison-Wesley, 1999). Chapters 6 and 11 contain more information about compute servers:
http://www1.fatbrain.com/asp/bookinfo/bookinfo.asp?theisbn=0201309556
JavaSpaces Principles, Patterns, and Practice is also freely available on the Web:
http://java.sun.com/docs/books/jini/javaspaces/JSBookExamples.zip
- For nitty-gritty API details, see the definitive references are the Jini specifications from Sun Microsystems (starting with the Jini Entry Specification and the JavaSpaces Specification):
http://www.sun.com/jini/specs/
- The Jini specs are also conveniently provided in The Jini Specification (The Jini Technology Series), Ken Arnold, Bryan O'Sullivan, Robert W. Scheifler, Jim Waldo, Ann Wollrath, and Bryan O'Sullivan (Addison-Wesley, 1999):
http://www1.fatbrain.com/asp/bookinfo/bookinfo.asp?theisbn=0201616343
- Core Jini, W. Keith Edwards (Prentice-Hall, 1999) provides a more general treatment of every aspect of Jini technology:
http://www1.fatbrain.com/asp/bookinfo/bookinfo.asp?theisbn=013014469x
- For pointers to the JavaSpaces FAQ and other documentation, visit the Sun Microsystems JavaSpaces page:
http://java.sun.com/products/javaspaces/.
- To gain insight into the philosophy that underlies Sun's approach to distributed computing, read "A note on distributed computing," Jim Waldo, Geoff Wyant, Ann Wollrath, and Sam Kendall, Sun Microsystems TR-94-29:
http://www.sunlabs.com/technical-reports/1994/abstract-29.html.
"Make Room for JavaSpaces, Part II" by Eric Freeman was originally published by JavaWorld (www.javaworld.com), copyright IDG, January 2000. Reprinted with permission.
http://www.javaworld.com/jw-01-2000/jw-01-jiniology.html
Talk back!
Have an opinion? Be the first to post a comment about this article.
About the author
Dr. Eric Freeman is currently a director of engineering at Disney's Go.com and a fellow at Yale's Center for Internet Studies. Eric recently coauthored JavaSpaces Principles, Patterns, and Practice, the official Sun Microsystems Jini Series book on JavaSpaces, along with Susanne Hupfer and Ken Arnold. Previously, Eric was CTO at Mirror Worlds Technologies, which builds products based on his work with David Gelernter at Yale University.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)