
Exploring the Java Data Mining API
Queries and navigation represent the key ways we interact with data today. A query applies expressions—written in a query language, such as SQL or XPATH—to a data set, and produces a subset of that data. Navigation allows one to traverse relationships between data items via direct references. Examples of traversal include clicking on a URL or following object references.
Queries and navigation both assume that relationships between data are known in advance. In case of a query language, for instance, the relationship between a company and its employees is represented with a link between company and employee IDs. With navigation, a Company object might produce a collection of Employees, and each Employee can be reached by iterating through that collection.
Relationships between data items, however, are not always known in advance, especially in large databases. Subtle relationships between possibly hundreds of data attributes may collectively tell a story that queries or navigation alone cannot reveal. In such situations, instead of querying or navigating, you may wish to mine the data to bring those hidden relationships to life.
Data mining "is a process for finding patterns and relationships in the data, and using that knowledge to classify new data or gain insights into that data," says Mark Hornick, Oracle Senior Manager for Data Mining Technologies and spec lead for the Java Data Mining API, or JDM (JSRs 73 [1] and 247 [2]).
Until recently, data mining remained the domain of highly skilled specialists. Developer and business tools, however, have started to bring data mining within the reach of any developer and user interested in gaining insight from large data stores. If that trend continues, data mining will occupy an increasingly important role in the arsenal of an enterprise developer tasked with building data access applications.
Data-mining tools were traditionally built either in-house, or provided in products with vendor-specific interfaces. As a result, Java applications had no standard way to interact with data-mining software. The situation was similar to accessing databases prior to the JDBC standard: Each application had to rely on product-specific APIs for data access. The Java Data Mining API (JDM) defines a common Java API to interact with data-mining systems. JDM is best understood as "JDBC for data mining." "JDBC is a very popular API, and we'd like to see JDM be similarly used for accessing data-mining capabilities from vendor products, whether the data be in databases or flat file systems," says Oracle's Hornick.
Because data mining is a complex set of activities, the initial JDM specifications left several important data-mining functions to a future JDM spec version. That allowed JDM 1.0 (JSR 73) to reach final specification stage in August, 2004, and subsequently to find its way into commercial implementations. JDM 2.0 (JSR 247) was accepted to the JCP on June of this year, and it aims to define many additional capabilities left out of the 1.0 spec.
The rest of this article introduces data-mining concepts, and provides a code example that maps those concepts to JDM classes and usage.
Turn data into knowledge
A key purpose of data mining is either to help explain the past, or to try to predict the future based on past data. To those ends, data-mining techniques help identify patterns in a vast data store, and then build models that concisely represent those patterns. Such models capture the essential characteristics of the underlying data, helping humans gain new insights—and knowledge—from that data.
Data mining differs from other data access mechanisms both in process and technique. "When you formulate theories and test them out, that's deductive reasoning. By contrast, data mining is inductive," says Oracle's Hornick. "You often hear people say, 'Oh, I do data mining.' But they're just doing queries. Even a complex SQL query executing over large amounts of data is merely the extraction of detailed summary data. OLAP [online analytic processing][3] allows you to do slicing and dicing of data cubes, but that's still not data mining. Data mining gives you the ability to look into the future, to do predictions, to extract information that an individual would not have had any real capacity to discern because of the volume of the data and the complexity in that data."
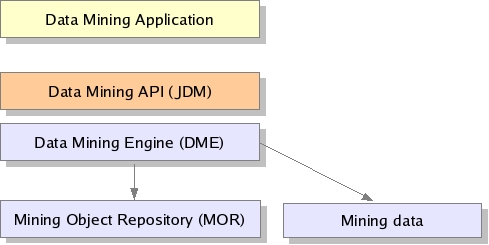
A typical data-mining system consists of a data-mining engine and a repository that persists the data-mining artifacts, such as the models, created in the process. The actual data is obtained via a database connection, or even via a filesystem API. A key JDM API benefit is that it abstracts out the physical components, tasks, and even algorithms, of a data-mining system into Java classes.
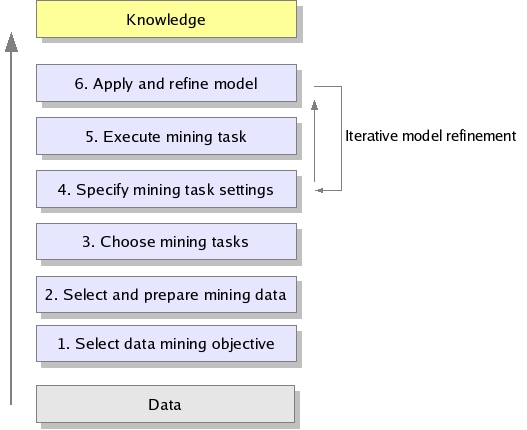
Building a data-mining model typically starts with identifying recurring patterns in the data, and then distilling those patterns in a way that helps communicate them to humans or other machines. Models can take the form of a graphical representation, a set of equations, a neural network, or even a collection of rules. Models can be applied to new data, or evaluated and refined in the presence of ever larger data sets. The process can be summarized as follows:
-
Decide what you want to learn. The first, and most important, step is to decide what kinds of new knowledge or insight you want to gain from the data. The more specific you are, the more likely your data-mining process succeeds.
For instance, you may want to find out what factors led to a successful holiday sales promotion so that you can recommend strategies for future sales events. Or, you may wish to predict which customers are likely to buy a product you are about to introduce. In another instance, you may want to identify potential galaxies from a digital sky image database. Or, you may want to learn what articles to show together on a Web site to improve user experience.
-
Select and prepare your data. Once you've decided on the objective, you must identify the data that you think may help you achieve those goals. For instance, sales records and lists of advertising placements may be relevant to deciding what factors contributed to sales success. Web server log files, in turn, may be relevant to gaining insight into Web site usage. Initially, you may wish to select only the subset of the available data that you believe is most representative of what you wish to find out. You can later select additional data subsets to improve your initial findings.
Relevant data sets are seldom in the format suited to data mining. Often, you must transform that data, possibly cleaning it—eliminating incomplete records, for instance—and sometimes also preprocessing it. For example, you may need to combine sales data with customer demographic data, or Web log records with user account data.
-
Choose and configure the mining tasks. Next, you should decide on the specific data-mining task to perform. For instance, you may wish to cluster users together that visited similar Web pages, and then derive association rules that show how those users and pages are related. Those rules, in turn, can help evaluate, or "score," new Web pages and readers, and decide what links to place on those pages for new visitors. For a sales promotion, the task may be to select the features most relevant to a successful sales event, and then quantify how those features impact sales.
Having selected a mining task, you would then configure that task with parameters suitable for the task. In the JDM API, such configuration is specified with settings.
-
Select and configure the mining algorithms. Settings allow you to select algorithms for a mining task. Many data-mining algorithms are available for a given task. Algorithms differ not only in the accuracy of their end-product, but also in the computational resources they require.
Many data-mining tools are able to automatically match algorithms to a desired data-mining objective; for instance, a clustering algorithm to create data clusters, or an association-rules algorithm to identify association rules.
-
Build your data-mining model. The output of executing a data-mining task is your data-mining model: That model, ideally, is a representation of your data suited to your objective. For instance, the model might be a neural network, a decision tree, or even a set of rules understandable by humans.
-
Test and refine the models. You might create several models, evaluate the accuracy of each model with past data, and possibly select a "best" model for your purpose. One way to evaluate models is to apply the newly gained insight to past data, and compare that with results that would be obtained without the aid of that insight, for instance by random sampling. Ideally, your newly gained insight should produce improved results—a "lift," in data-mining argot.
-
Report findings or predict future outcomes. Finally, you could either report your findings—think PowerPoint—or use your data-mining models to predict future results. In some cases, you may build systems that automatically improve their data-mining models with new data, or systems that take actions in the presence of a continuous stream of new information.
The current trend is towards automating as much of this process as possible. "Even those not expert in data mining can reap the benefits of data-mining technologies," says Oracle's Hornick. "In the [JDM] standard, [users may have the] system determine automatic settings. We provide [in the JDM API] functions for classification and clustering, for instance."
Using the JDM API
A typical data-mining project might start with a data analyst—someone very familiar with the problem domain—using JDM to explore what models and model building parameters work best. The analyst could persist those models in the mining object repository (MOR), which would then become part of the specifications a developer can use to deploy a data-mining solution. The specs might include other artifacts as well, such as scoring techniques or the algorithms to use, for instance.
To create a data-mining model, an analyst or developer would follow a few simple steps that map the process described in the previous section to JDM interactions. The steps below are illustrated with code snippets later in the article:
-
Identify the data you wish to use to build your model—your build data—with a URL that points to that data.
-
Specify the type of model you want to build, and parameters to the build process. Such parameters are termed build settings in JDM. The most important build setting is the definition of the data-mining task, such as clustering, classification, or association rules. These tasks are represented by API classes. Additionally, you may also specify the algorithms to use in those tasks. If you don't care about a specific algorithm, the data-mining engine may select one for you, based on the desired task.
-
Optionally, you may wish to create a logical representation of your data. That allows you, for instance, to select certain attributes of the physical data, and then map those attributes to logical values. You can specify such mappings in your build settings.
-
Another optional step allows you to specify the parameters to your data-mining algorithms as well.
-
Next, you create a build task, and apply to that task the physical data references and the build settings.
-
The JDM API allows you to verify your settings before running a build task. That lets you catch errors early, since a build tasks may run for a long time.
-
Finally, you
executethe task. The outcome of that execution is your data model. That model will have a signature—a kind of interface—that describes the possible input attributes for later applying the model to additional data.
Once you've created a model, you can test that model, and then even apply the model to additional data. Building, testing, and applying the model to additional data is an iterative process that, ideally, yields increasingly accurate models. Those models can then be saved in the MOR, and used to either explain data, or to predict the outcome of new data in relation to your data-mining objective.
The following code example, based on the JDM 1.0 specification, creates a model that predicts which customers would purchase a certain product. Suppose that you have a database of existing customers, with each record consisting of many customer attributes. You could build a model with that data to help explain how certain customer or purchase attributes impact the likelihood of a customer purchasing your product. You could later use that model to predict the likelihood of new purchases.
Suppose a customer attribute, purchase, indicates whether a customer has purchased the product, with two possible values: Y and N. Attributes that correspond to such discrete values are termed categorical attributes: They tell which of a given set of categories an item belongs to (buyers and non-buyers, in this case).
For future customers, we would want our model to predict the value of the purchase attribute. In other words, the objective of our data mining is to create a model that classifies customers based on the value of the purchase attribute. Not surprisingly, the data-mining task we will use is classification. The classification task has a target, which is the attribute we try to predict (purchase, in this case). All other customer attributes will be used by the classification as predictors of that target.
The mining data for this task can be located in a flat file, or in a database table. In either case, the data-mining system needs to know how to map attributes of the physical data to logical attributes. For example, the purchase attribute may be labeled "hasPurchased" in the actual physical data set. In addition, we need to tell the data-mining engine that the purchase attribute is a categorical attribute. You can specify such mappings via the settings supplied to the classification mining task. The code below shows how to map physical data to logical values, and also how to specify data-mining task settings.
The example assumes that you've already obtained a connection to a data-mining engine, perhaps via a JNDI call. A JDM connection is represented by the engine variable, which is of type javax.datamining.resource.Connection. JDM connections are very similar to JDBC connections, with one connection per thread.
Having obtained a connection to the data-mining engine, the next step is to define the physical data you wish to mine. The build data is referenced via a PhysicalDataSet object, which, in turn, loads the data from a file or a database table, referenced with a URL. The JDM specs define the acceptable data types and format of the input file. You would use a PhysicalDataSet for both model building and to subsequently test and evaluate your model:
PhysicalDataSetFactory dataSetFactory
= (PhysicalDataSetFactory) engine.getFactory("javax.datamining.data.PhysicalDataSet");
PhysicalDataSet dataSet =
pdsFactory.create(
"file:///export/data/textFileData.data",
true);
engine.saveObject("buildData", dataSet, false);
Based on the physical data, we can define a logical data model. In this example, we specify that purchase is a categorical attribute of the data:
LogicalDataFactory logicalFactory
= (LogicalDataFactory) engine.getFactory("javax.datamining.data.LogicalData");
LogicalData logicalData = logicalFactory.create(dataSet);
LogicalAttributeFactory logicalAttributeFactory = (LogicalAttributeFactory)
engine.getFactory("javax.datamining.data.LogicalAttribute");
LogicalAttribute purchase = logicalData.getAttribute("purchase");
purchase.setAttributeType(AttributeType.categorical);
engine.saveObject("logicalData", logicalData, false);
Next, we proceed to specify settings for building the model. Since the mining task we wish to perform is classification, we create settings for classifications, including specifying naive Bayesian as the algorithm. This example has the single target attribute of purchase. Note that the algorithm itself accepts settings via an algorithm-specific settings object:
ClassificationSettingsFactory settingsFactory = (ClassificationSettingsFactory)
engine.getFactory("javax.datamining.supervised.classification.ClassificationSettings");
ClassificationSettings settings = settingsFactory.create();
settings.setTargetAttributeName("purchase");
NaiveBayesSettingsFactory bayesianFactory = (NaiveBayesSettingsFactory)
engine.getFactory("javax.datamining.algorithm.naivebayes.NaiveBayesSettings");
NaiveBayesSettings bayesSettings = bayesianFactory.create();
bayesSettings.setSingletonThreshold(.01);
bayesSettings.setPairwiseThreshold(.01);
settings.setAlgorithmSettings(bayesSettings);
engine.saveObject("bayesianSettings", settings, false);
Having specified the settings, we create a build task. As an optional step, the JDM API allows you to verify the settings before starting to build the model. We will not handle verification errors in this example:
BuildTaskFactory buildTaskFactory =
(BuildTaskFactory) engine.getFactory
("javax.datamining.task.BuildTask");
BuildTask buildTask = buildTaskFactory.create("buildData", "bayesianSettings", "model");
VerificationReport report = buildTask.verify();
if( report != null ) {
ReportType reportType = report.getReportType();
//Handle errors here
}
//If no errors, save build task
engine.saveObject("buildTask", buildTask, false);
//Execute the build task
ExecutionHandle handle = engine.execute("buildTask");
//This may take a long time. So wait for completion
handle.waitForCompletion(Integer.MAX_VALUE);
Finally, we can access the resulting model:
ExecutionStatus status = handle.getLatestStatus();
if (ExecutionState.success.equals(status.getState())) {
ClassificationModel model = (ClassificationModel) engine.retrieveObject( "model", NamedObject.model );
}
Data mining for the masses
Proposed new features for JDM 2.0 include mining capabilities for time-series data, which is useful in forecasting and anomaly detection, such as in security. Another proposed feature will allow you to mine unstructured text data, and there are plans to extend the JDM's scope to data preparation and transformation as well.
While the JDM 1.0 API has been an approved standard for almost a year, only a handful of products implement portions of the standard at the time of this writing. "Oracle has a product based on JDM 1.0. There are other vendors as well . . . Many commercial vendors are waiting on the sidelines to find demand for data mining, and will then implement [JDM] in their own products," says Hornick.
That demand may not be far in coming as data mining is becoming an increasingly mainstream data management task. The Basel Committee, established by the central bank board of governors of the Group of Ten countries to provide regulatory oversight and best practices for the world's financial institutions, recently allowed banks to reduce the amount of their mandatory reserves if they can build their own predictive data models to accurately assess the risk of defaults.[4] Data mining is a key component in building such models.
The JDM itself may contribute to increased demand for data mining. An analogy with databases may illustrate the point: Prior to ODBC and JDBC, database access was possible only via proprietary vendor interfaces. Not only did that render database-aware applications dependent on specific database products, vendors often charged extra for those interface components. ODBC and JDBC eliminated those barriers, making database access universal and ubiquitous. The JDM API might similarly make data-mining capabilities available to any Java application. JDM spec lead Hornick puts it this way: "Our goal [with the JDM] was to bring data mining to the masses."
Resources
[1] Java Data Mining API 1.0, JSR 73
http://www.jcp.org/en/jsr/detail?id=73
[2] Java Data Mining API 2.0, JSR 247
http://www.jcp.org/en/jsr/detail?id=247
[3] "What is OLAP?" From the OlapReport
http://www.olapreport.com/fasmi.htm
[4] The Basel II banking regulations
http://www.bis.org/publ/bcbsca.htm
[See also]
Micheal Lesk, How Much Data is There in the World?
http://www.lesk.com/mlesk/ksg97/ksg.html
Vannevar Bush, As We May Think
http://ccat.sas.upenn.edu/~jod/texts/vannevar.bush.html
MyLifeBits project
http://www.research.microsoft.com/barc/MediaPresence/MyLifeBits.aspx
Advances in Knowledge Discovery and Data Mining, Usama M. Fayyad, Gregory Piatetsky-Shapiro, Padhraic Smyth, Ramasamy Uthurusamy, editors. MIT Press, 1996.
http://www.amazon.com/exec/obidos/ASIN/0262560976/
Predictive Data Mining: A practical guide, Sholom M. Weiss, Nitin Indurkhya, Morgan Kaufmann, 1997.
http://www.amazon.com/exec/obidos/ASIN/1558604030/
KDnuggets (data mining portal)
http://www.kdnuggets.com/
ACM Special Interest Group on Knowledge Discovery and Data Mining (SIGKDD)
http://www.acm.org/sigs/sigkdd/
Talk back!
Have an opinion? Be the first to post a comment about this article.
About the author
Frank Sommers is a Senior Editor with Artima Developer. He also serves as chief editor of the Web zine ClusterComputing.org, the IEEE Technical Committee on Scalable Computing's newsletter, and is an elected member of the Jini Community's Technical Advisory Committee. Prior to joining Artima, Frank wrote the Jiniology and Web services columns for JavaWorld. Frank is also president of Autospaces, a company dedicated to providing service-oriented computing to the automotive software market.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)