
In his witty account of cluster computing, In Search of Clusters, author and IBM Distinguished Engineer Greg Pfister notes that software, not hardware, stands in the way of constructing high-availability, high-performance systems from inexpensive commodity components. Since the publication of Pfister's book seven years ago, high availability and scalability have become a requirement not only for large enterprises processing millions of transactions an hour, but equally for medium and small businesses.
Scalable and highly availabile systems traditionally required not only expensive hardware, but specially trained technical operators carefully watching over those systems, tuning them, and ensuring their smooth operation. Since smaller firms could not afford that expense, they had no choice but to compromise on system availability and choose less capable hardware and software for their information processing needs.
However, a quiet revolution is changing all that, making high-availability systems a reality even for the smallest enterprises. This article describes a high-availability, scalable clustering technique using Jini technology. As a tool for dynamic networking, Jini technology found a niche as middleware in support of highly available and scalable enterprise systems that operate on clusters built on commodity hardware. The architecture presented in this article, and developed by Boomi Software, uses Jini technology in that manner, and forms the core of that company's system integration server product.
Service-Oriented Cluster Virtualization
A cluster is a collection of independent computers working together in support of a common task. A cluster's key benefit is that adding more nodes to a cluster increases the cluster's computing capability while also making the cluster more resilient to failure. Because a cluster can be constructed from very low-cost hardware, clustering emerged as a popular high-availability and scalability technique.
Each node in a cluster maintains its own CPU, memory, and often even storage. Node hardware can come in great diversity, from specialized blade computers to off-the-shelf commodity PCs. Each cluster node runs its own operating system copy. The interconnection network between the nodes can also assume a large variety, from 100Mb/s Ethernet to 10Gb Ethernet, or specialized cluster networks, such as Myrinet[1].
Several techniques help transform the collection of independent computers in a cluster to a more or less unified computing device. A favorite clustering technique aims to virtualize cluster resources. Virtualization abstracts out hardware and operating system resources from a single node to the level of a cluster. Consider, for example, a file system that could be virtualized by mounting a shared storage device identically on every cluster node. Thus, a file saved on the virtualized filesystem mounted at, say, /home/user, would be accessible on any cluster node with an identical file path.
Virtualized cluster resources, such as a distributed and networked file system, offer shared capabilities by means of services. Those services, in turn, correspond to processes. A file system daemon process, for instance, offers a file system service. Each cluster node running the appropriate network client can invoke the file system service across the network and make the file system available locally.
Common cluster services, such as a file system or even I/O device access, are often defined by means of a network communication protocol. For instance, the Network File System (NFS) defines a network mounting protocol in terms of message exchanges between the NFS daemon process and its clients.
While virtualization of cluster resources has traditionally been achieved via operating-system or protocol-specific means, a higher-level service virtualization layer often hides the details of a service's communication protocol, and instead exposes that service based on a conceptual service type. For instance, invoking the ls command on a file system produces similar results whether the file system is mounted via the NFS daemon or is local to the machine. Of importance to the ls command is the kind, or type, of service it invokes, and not any specific file system protocol.
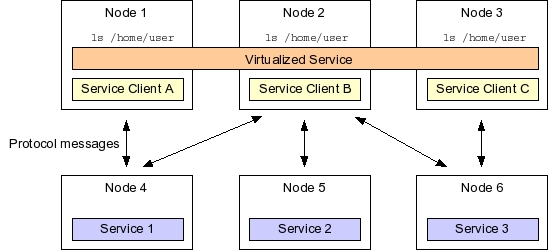
Application Clustering
Service interfaces on a cluster can define not only lower-level services, such as a filesystem, but also more specialized services in support of an application domain. An example is Boomi's cluster architecture that defines a series of services supporting dynamic system integration. A fundamental problem of system integration is the need to access various data sources, accept input from those data sources, translate that input into another data format, and then present the results to employees or systems that can act on those results.
Boomi's cluster architecture breaks up system integration processes into discrete tasks, such as those responsible for data input, rules execution, data transformation, or providing output. Services representing those tasks can then be distributed on cluster nodes and executed in parallel.
Such distribution yields improved reliability. For example, implementations of a service that transform an incoming purchase order into an email and inserts that email in a mail queue, can be deployed on multiple cluster nodes. Since instances of that data transformation service are interchangeable, any of those service instances can handle an incoming request. Because that data transformation service is offered by a collection of several redundant transformation service instances, the failure of a single cluster node does not also cause the data transformation service on the cluster to fail.
As well, cluster-based distribution of redundant services provides load balancing, since incoming messages, such as purchase orders, could be handled by a service instance on the least utilized node. Finally, cluster-based distribution of system integration tasks provides almost linear scalability: adding twice as many cluster nodes results in twice the throughput, not considering added communication overhead.
Distributing such services on a cluster, however, introduces the problem of locating instances of a service running on certain cluster nodes and accessing those services from other nodes. If such services would have to be managed on the level of individual nodes, the scalability and reliability benefits of the cluster could be obtained only at the cost of increased system administration. In addition, if dealing with node failure required redistribution of workload by a system administrator, operating the cluster would prove a costly enterprise.
To automate such cluster management chores, Boomi turned to Jini technology. As a dynamic networking tool, Jini technology aids cluster management by its ability to expose implementations of Java interfaces as services on a cluster network, and by enabling clients to locate a service based on the service's type.
Type-Based Service Lookup with Jini Technology
Jini technology makes type-based service definition and lookup explicit by requiring that Java interface type define a network service: A Jini service implements one or more Java interfaces, and the Jini service lookup infrastructure enables network clients to find services based on what Java interfaces a service implements. Jini technology's dynamic service lookup capability reduces cluster administration chores. Instead of looking in configuration files to locate services on the network, clients can use Jini lookup services to locate services dynamically.
To appreciate that benefit, consider the find command present on most Unix systems. find takes a directory path and a file pattern as arguments, and finds files with names matching that pattern on the specified directory tree. If a file system specified to find was not mounted in advance on the node where find is executed, the command will, of course, not search for files on that unmounted system.
But a possible Jini version of find would not have to contend with that limitation. Jini technology's service lookup capability would allow a Jini version of find to dynamically locate file system services on the network, invoke those services, and attempt to search those remote file systems as well.
Jini lookup services serve as central rendezvous points for Jini service lookup, and are themselves Jini services. Clients use the Java interface type, in addition to optional service attribute values, to find Jini services registered in lookup services on a cluster. Implementations of those interfaces, in turn, must register a proxy object with lookup services.
A Jini service's proxy object plays a crucial role in how a client invokes that service. Such proxies are serialized Java objects that implement the service's Java interface. Thus, when a client locates a matching service registration in a Jini lookup service, the client retrieves that service's proxy object, and then invokes service methods on the proxy. The proxy may implement the functionality completely in the proxy, or interact with a remote service implementation via any communication protocol possible between proxy and remote server. As a result, the client does not have to care about what communication protocol to use with a service, because such protocols are hidden away into the service's proxy.
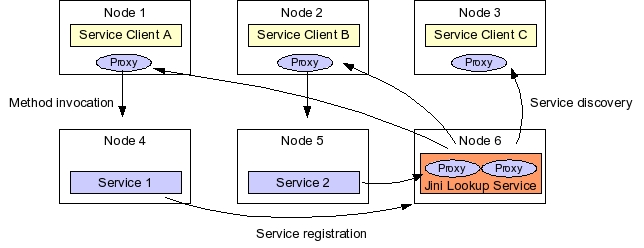
A fundamental assumption of a Jini system is that the network is not reliable. One way a Jini system deals with an unreliable network is by leasing references to remote network resources to clients. A lease places a time limit on a client's use of a network's resources, such as a Jini service proxy, or the Jini lookup service. Lookup service registrations are also time-limited: A service must renew the lease of its proxy in a lookup service, or the lookup service will purge that proxy.
The lease-based access to resources defined in the Jini architecture fits well with the dynamic nature of a cluster. Since cluster nodes can fail at any time, a failed node's service registrations will be purged by lookup services. As well, introducing a new cluster node involves merely installing and starting new service implementations on the new node: Those services will register their proxies with the cluster's lookup services, making the new node available to clients without further administrative work.
Service-Oriented System Integration
Boomi's cluster architecture exploits the dynamic nature of Jini networking to provide high availability and failover. Boomi defines system integration services with Java interfaces, and registers implementations of those services in Jini lookup services on the cluster.
Interaction between services starts by a client performing a Jini service lookup based on the required service's type. Services can be deployed on the cluster in a redundant fashion. Since each service implementation registers a proxy that implements the service's Java interface, the client can retrieve and use any implementation's proxy. If a node fails, or is powered down, the service implementations on that node will not renew their lookup service registrations, causing the cluster's lookup services to purge those service proxies. Since a client's access to a service proxy is also based on leases, the client will have to locate a new service's proxy from the Jini lookup services. Dynamic service location and lease-based access to resources inherent in Jini networking thus provide the foundations of Boomi's high-availablity and failover infrastructure.
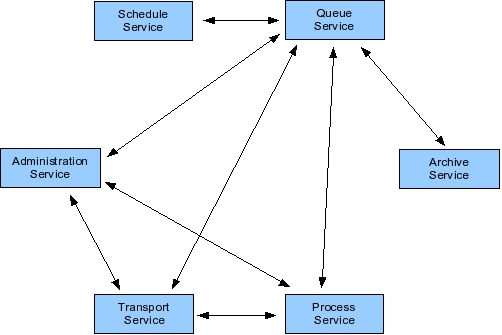
In Boomi's system integration architecture, a layer of transport services represents the gateway between the Boomi server and external data sources. Transport services act as I/O for the Boomi system. For instance, HTTP transport occurs via an HTTP-specific transport service, FTP transport through an FTP transport service, and input into a database is arranged via a database transport.
As messages enter the system, they are placed into a queue managed by a queue service. The queue service acts as a message delivery system, and is responsible for persisting data received from various transports to guarantee message delivery. Thus, the queue service is used by all other services. The queue service relies on a relational database to persist message data.
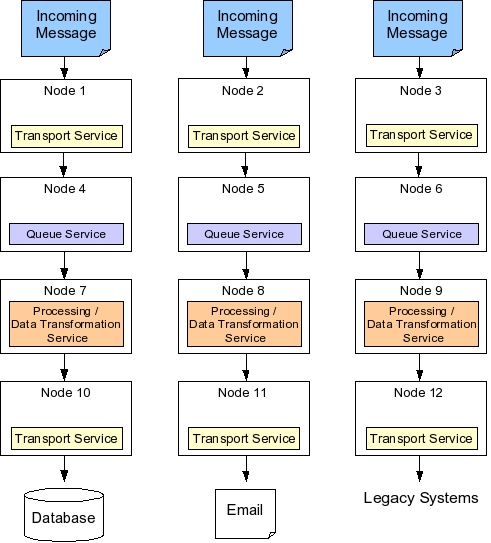
While the database may form a single point of failure, in practice Boomi's system is deployed on a clustered database. All incoming data, as well as interim processing results, are saved in the database. When the queue service restarts after a crash, it first looks in the database for yet unprocessed data, and invokes services responsible for processing those messages.
Messages in the queue are eventually processed according to message type, message origin, and rules corresponding to additional message parameters. Such processing occurs by process services that not only transform data, but also route data to destinations specified by rules. Thus, process services form the core of the system integration functionality.
Boomi's process services implement about fifteen system integration patterns, such as data transformation, intelligent routing, decision validation, exception handling, or dynamic messaging. For each process service, users specify via a graphical rules designer what input data to expect, what transformation actions to take on what message types, and where results should be routed.
Events in Boomi's system occur not only in response to arriving messages, but also in an automated fashion induced by a Jini scheduling service. This service is analogous to the Unix cron daemon, and fires off events at specified intervals. General administrative responsibilities, in turn, are performed via a Jini administration service that controls configuration-level properties, such as where the database is located, and provisions security access. The administration service is also responsible for logging.
Finally, Boomi's Jini archiving service takes data out of the live data set maintained by the queue, and puts that data on a secondary storage device for historic preservation. For instance, the archiving service may pull data out of the database if a data item is older than a specified number of days, preventing the live database from becoming too large.
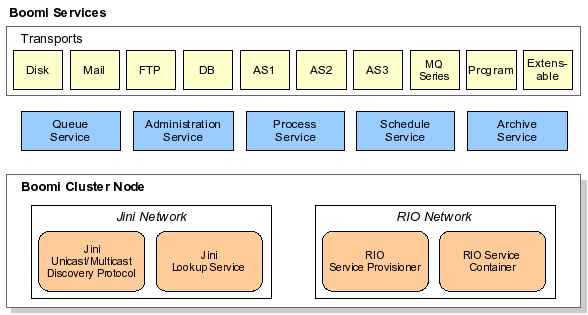
When a service boundary is crossed, Jini discovery, lookup, and remote method invocation facilitates service interaction. As an example, suppose that data needs to be read from a directory, transformed to a different format, and then written out to the directory again. In this example, the transport service reads the data in from the directory, and hands that data off to the queue service. The queue service persists the data in the database management system so that the data has guaranteed delivery: If the system fails at any point, that data item can be resent. Next, the queue service sends that data to the process service, which transforms the data to the desired format. The process service then places the data back into the queue. Lastly, the queue hands the results back to a transport service, which then writes out the data to the directory.
In this scenario, the queue service must find the administration service to obtain information about the system's database, and to download the needed JDBC driver. The queue service also has to locate transport services to send and retrieve data, and process services to hand data to for processing. As well, the queue service finds the archive service and passes to it data that is ready to be archived. Once the data is in the archive service, the archive service might seek additional archive services on the network in order to replicate the data.
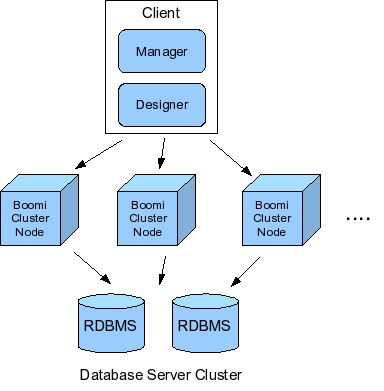
Boomi's cluster-based service deployment relies on the open-source Jini Rio project. Rio defines the cluster's desired operation in a declarative fashion. A Rio cluster configuration might specify how many instances of the process or transport services should be running. Rio's runtime infrastructure monitors the cluster and tries to ensure that desired cluster state. Suppose, for instance, that an administrator requests that four instances of the HTTP transport service be running. If a cluster node executing an HTTP transport service crashes, Rio starts a new HTTP transport service instance on an available node.
Boomi's administration, schedule, and queue services are considered singleton services: while they are deployed to cluster nodes, only one instance runs at a given time. On the other hand, the Boomi process service that does most of the heavy lifting on incoming data, is often clustered. As well, clustering the archive service provides multiple backup mechanisms across different cluster nodes. That way, archived data is replicated across multiple machines.
Why not J2EE?
Before turning to Jini technology, Boomi considered J2EE as the foundation of their system. They felt, however, that the J2EE specs didn't define the kind of system they wanted to achieve, especially because of restrictions on communication patterns with external systems from inside a J2EE container. They felt they would have had to jump through hoops in application-to-application communication, and have to introduce components of their product outside the J2EE architecture. Jini technology, on the other hand, imposed no such restrictions.
More important, Boomi's customers are mid-market and smaller firms that lack in-house technical knowledge to operate a full-fledged J2EE environment. Many small firms do not even use Java in their business infrastructure. Thus, a Java based-solution had to be presented in such a way as to allow non-Java experts to operate the system, including the system's high-availability and clustering features. Because Boomi could not rely on in-house clustering and high-availability systems knowledge, it had to provide these features entirely from within the software. Finally, Boomi's customers use a variety of operating systems, and therefore implementing clustering in an OS-specific way would have limited their product's appeal.
By Boomi's account, the Jini-based solution achieved their objective of providing transparent clustering services. Approximately ninety percent of their customer are not aware of Jini networking's presence in the system. And the system proves to be reliable with minimum administration requirements. Boomi's choice to not build on J2EE had an additional benefit: Since customers are not required to purchase a J2EE server license with the product, Boomi's solution also saves their customers money.
Summary
The most interesting aspect of Boomi's solution may simply be that it leverages Jini dynamic networking technology to provide enterprise quality service from an all-Java system in an environment where J2EE is not an option. Most people in similar situations would either turn to J2EE to help them achieve scale, failover, and load balancing for an enterprise Java system, or try to obtain those system properties from operating system-specific tools. Many of those solutions are presently too costly, or too complex for smaller and medium size firms.
By exploiting the parallelism inherent in the system integration process, Boomi was able to offer a high-availability and scalable solution entirely within its own software offering. Its customers can use their existing servers, and do not have to be experts in cluster setup and maintenance. As a system's load increases, customers can scale the system up simply by introducing additional cluster nodes. While software is still the bottleneck in harnessing the collective power of commodity, off-the-shelf hardware, Boomi's system demonstrates that rethinking a problem from the vantage point of parallelism and scalability can yield surprisingly effective solutions.
Acknowledgements
We would like to thank Rick Nucci and Mitch Stewart at Boomi Software, for providing a description of their Jini-based system integration architecture, and to Sun Microsystems, Inc., for
Resources
Boomi Software.
http://www.boomi.com
Jini Community Web site
http://www.jini.org
Myricom's Myrinet interface
http://www.myri.com
Talk back!
Have an opinion? Readers have already posted 12 comments about this article. Why not add yours?
About the author
Frank Sommers is an editor with Artima Developer. He is also founder and president of Autospaces, Inc., a company providing collaboration and workflow tools in the financial services industry.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)