
An Interview with Geert Bevin
Geert Bevin is founder of the RIFE Web application framework project. In his day job, he is the CEO of Uwyn, a custom application development company that focuses on Web applications, open-source, Java, and rich Internet technologies. He also started, or contributed to, projects such as Bla-bla List, OpenLaszlo, JHighlight, JavaPaste, Drone, Bamboo, Elephant, RelativeLayers, and Gentoo Linux.
The RIFE project recently released the 1.5 version of the framework. In this interview Bevin talks about how the RIFE framework came about, discusses the framework's various layers, RIFE's approach to configuration and persistence, and the role of continuations in enterprise applications. Along the way, he introduces some of the new features in RIFE 1.5.
Frank Sommers: What is RIFE, and how does it compare to other enterprise Java frameworks?
Geert Bevin: The funny thing is that RIFE didn't start out as a framework with an enterprise focus. We were a small Belgian company doing dynamic Web applications, and we decided to use Java about five years ago. At that time developing enterprise Java applications was a fairly convoluted process, and not many frameworks were there to make life easier.
Prior to that, we had chosen PHP for a big Web application. That choice turned out well for a while—until we tried to maintain the application. Even though productivity [with PHP] was high, maintainability was horrible, and maintaining that application became a huge hassle. It was still the early days of PHP 4, and the PHP project had a habit of fixing critical bugs in minor version upgrades. Some of those changes made the APIs incompatible with previous versions. Since PHP had no static type checking or a compilation phase, you had to verify every page manually to see if that page still loaded after a minor upgrade.
Maintaining that PHP application started to create problems for us, and that's when we decided to go back to Java, and apply what we thought were good principles from doing our PHP work and earlier Java work. We applied that into a framework, and that framework became RIFE. So RIFE is a collection of experiences over the years.
Many people have asked us what RIFE stands for, the answer is simple—it stands for nothing really. I looked through the dictionary to find a short word that looked nice and then just capitalized it to make it stand out. RIFE was just some kind of wishful thinking that is being realized now.
For example, I just learned that Facebook, the seventh most visited site in the United States and used by eighty-five percent of all college students, published a developer API, and they selected RIFE to implement the Java demo application, FaceBank. It is a virtual tracker of how much money you and your friends owe each other. To integrate with the real Facebook authentication and account system, they simply customized two classes of RIFE's authentication framework, and defined all the other functionality as an independent application. The customizations are published on their developer site.
RIFE's main focus is to be a full stack that makes development productive. One way RIFE achieves that is by having reasonable defaults for all the layers of a Web application. Those defaults work well ninety percent of the time, helping to reduce configuration requirements for your application. But RIFE's configurations also require that you declare certain things from the beginning.
Some people criticize RIFE for not being like Ruby on Rails, where you can just start coding and have something up and running. We advocate RIFE as a productive framework, but we require that you declare, for example, your controllers—what we call elements—and the relationships you have between them.
Why? Because we've been bitten so many times by the maintainability issue. We think that declaring certain things beforehand makes your application easier to maintain—for instance, it forces you to think of how state is being managed in your application. And it makes it much easier for other developers to take over, or for yourself to maintain the application over time. Additionally, we found that by having such centralized declarations, the power and capabilities of the framework are dramatically enhanced: The framework can infer a lot of information from the configuration.
Frank Sommers: Can you give an example of what kind of declarations help the framework?
Geert Bevin: A very simple example is your page URLs. One of the main problems in coding Web applications is how to put a URL into a form or a link: How do you insert that URL there so that if you reuse that application, the URL remains consistent? For us, that was very important because we work on multi-language sites, and we have customers who ask for specific localized URLs. We have to be able to change a URL into a French URL, but keep the same functionality. For that to work, you should be able to specify a URL in one place, and the framework should ensure the consistency of that URL in the view. RIFE allows you to do that.
Another example where some externalization is important is when you want to run several instances of the same application in the same servlet container. In that situation, the prefixes for your Web applications will change based on the context. Over the years, developers dealt with that by using relative URLs, but that requires everybody to be careful coding those URLs directly. We think that leads to a brittle environment.
An advanced example has to do with elements, which is RIFE's term for controllers. If you have all your elements declared, along with the state transitions between them, your framework can really help you with state handling. It's a bit similar to what Spring Webflow does, with their flow language, allowing you to have components that are completely agnostic of the state that is active at a point in time. They just get that state from the framework. If you later want to reuse components in another context, say, as a portlet or as a widget, the only thing you have to do is re-wire the state, but your components continue to function without any changes to the code. Thus, elements, or controllers, and their interaction is another area where we think it's important to externalize them and declare them independently.
Because maintainability is one of the key aspects of RIFE, that drives what the developer is required to set up. It's not like Ruby on Rails when you just start coding, and you see where you'll end up. There is also a small learning curve involved.
Frank Sommers: How do you decide what kinds of data to specify in external configuration files? Lots of developers use Struts, for instance, but I often find Struts' XML configuration cumbersome.
Geert Bevin: That depends on what you do with that [configuration] data. In Struts, configuration data doesn't do much besides defining navigation between pages, mounting your actions to URLs, and setting up form beans. There are other functionalities, but what you often see in Struts applications is just that. That doesn't give many benefits to the framework. It does a little bit, because you abstract out your URLs, as well as data submissions and navigation, but it's not a full stack that can be used everywhere in your application to drive behavior.
It's about finding a good set of configurations that really enhances productivity as well as maintainability. If you use a good set of declarations developers get a lot of functionality for free.
Frank Sommers: What are some of the things you get for free with the default declarations in RIFE?
Geert Bevin: Let me start at a high level, which is a sibling project called RIFE/Crud. It does a bit of what Rails has done with scaffolding. While Rails analyzes your table structure in the database and then let you call a script to generate some files that you can later modify, RIFE/Crud relies on a metadata model that attaches itself to your domain model. We call these constraints. That metadata model can drive every layer in the framework and is part of the core of RIFE. RIFE/Crud is just a consumer of that metadata.
A simple example is a bean with a customer name. Using the metadata constraints, you can attach a maximum length to that customer's name. That metadata can be used to generate a form with an input with the maximum length set. You can also generate validations from that metadata to ensure that when that form is submitted, you can verify that the maximum length is not exceeded.
Additionally, if you are not bound by a legacy database structure, you can generate your database tables from the metadata, too. That works similar to Rails, except that instead of going from the database, we go from the domain model, from the bean classes that were coded in Java.
RIFE has a functionality we call metadata merging: It allows you to keep your beans as POJOs without any dependency on RIFE. You declare a sibling class which has exactly the same name as the class, except for the Metadata suffix in the class name. That companion class allows you to have your metadata in Java, even as regular method calls, and the RIFE class loader will merge the two classes into one. For the purposes of any other framework you would use together with RIFE, such as Hibernate or Spring, your POJO doesn't have anything RIFE-specific attached to it, not even annotations. That keeps things very clean.
I mentioned earlier how useful declarations can be. While we think that some declarations are important, we don't think that you always have to write them by hand. Indeed, you can use metadata to generate those declarations at runtime without code generation. This is often referred to as meta programming. Having two separate layers—the metadata that can drive the declarations, and the declarations that actually drive the rest of the framework—you can always dip down to a lower layer if you need to customize things. It's not an all or nothing solution.
Older model-driven architectures would have you generate everything, and if your tool didn't support what you wanted to do, that was just too bad. With RIFE, you can always drop down a layer below and customize things. Each layer simply automates a certain functionality, and wraps low-level details at a higher abstraction level.
Frank Sommers: In addition to the metadata and configuration layers, what other layers are there in RIFE?
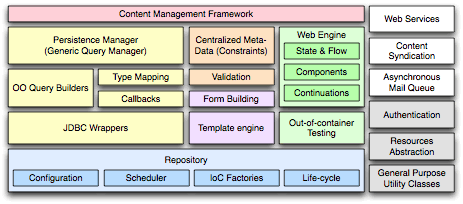
Geert Bevin: There is a layer that provides life-cycle management for your application: starting and stopping services with optional dependencies, application configuration with context detection, a cron-like scheduler, and IoC reference factories. Then there is the database layer, as well as a template engine layer. I already mentioned the meta data support through constraints that drives the whole framework, including a dynamic instance-based validation mechanism.
RIFE also includes a Web framework that supports continuations, provides for components with an action-based API, lets you do automated state handling, and with full support for out-of-container testing. RIFE also integrates content management with different storage back-ends for text, image and raw content entries. Finally, there is integration of external services, such as asynchronous email, RSS and Atom feed generation, SOAP and Hessian web-services, and Ajax support through DWR.
Frank Sommers: Let's talk about the persistence layer a bit. There are very successful persistence frameworks already. What does RIFE add in that department?
Geert Bevin: We took a very pragmatic approach to persistence. Indeed, there are great object-relational mapping tools, and we don't intend to compete with them. They have their very specific purposes: object-relational mapping and caching between the database and the application. These tasks are perfectly handled by these frameworks, and we don't need to reinvent that wheel.
Instead of providing the mapping of objects to relational databases, the way we approached persistence in RIFE is to wrap around what's already available. What many people would call a persistence engine in RIFE is a very thin layer that allows you to work with the direct mapping of beans to tables so that you can create a table from a JavaBean, insert an instance as a row, and retrieve beans from a database with a single method call on a bean manager class. The approach is really about wrapping, rather than mapping.
The initial wrapping that most people are aware of is similar to what Spring does with its JDBC templates. At the initial persistence engine layer, we provide templates with very common JDBC functionalities. An example is to fetch all beans from a database table. You get back a collection with all the beans populated, in one method call. That's something you do very often, if you have an exact mapping of your beans to database tables.
On top of that are several additional layers. The first one provides an object-oriented way of building your SQL queries. That's a bit similar to a product BEA had a couple of years ago. It's a fluent interface that allows you to create SQL queries without inlining the text of that SQL. That's how we handle database abstraction. We have an SQL dialect for many different databases, similar to what every other persistence framework has. That dialect is a simple text template. After you created an object graph of your SQL statements in Java, this layer uses those templates to generate the SQL for your database.
That goes hand-in-hand with a type mapping layer in RIFE that maps Java types to JDBC types and vice versa. That layer is not what you may expect, and does not manually require you to specify what column maps to what type. Instead, it's more like having a bean with a certain type for a property, and you may receive from the database another type for that property value. RIFE has a whole collection of conversions that will automatically convert the bean's property type to the database column's type. You don't have to set that up in most cases. If you have complex types to map, you can always drop down a layer and make exceptions, and then you don't rely on RIFE's typing.
Frank Sommers: If I already have an application that uses Hibernate or the JPA, how easy is it to make that app work with RIFE?
Geert Bevin: You can just continue using it—it's not one or the other. A lot of RIFE users use JDO or Hibernate. What we've seen users do is that when RIFE provides some functionality, they just use that. But when they need something more specialized, they, for example, use Hibernate, if Hibernate provides that functionality. The same is true for second-level caching. Object-relational mapping and caching are tough problems, but they have already been solved. We don't think we can add much more to that.
I should also mention that if you use what RIFE provides in persistence, then you can take advantage of another wrapper that integrates with our content-management framework. Users like RIFE's content management framework because, for example, it allows you to have rich media types represented as JavaBean properties. You can declare meta data constraints on the properties of the bean, such as an image mime-type with a certain width. Whenever that bean is saved, that property will not be saved in the database, but will be extracted to the content management framework. The framework will handle that rich media type and store it as a content entry. It will also automatically retrieve it from the content management framework if the content has the auto-retrieve flag turned on. Again, it's possible to drop down layers and interact with the content management framework directly to, for example, stream out that particular image directly to the browser without having to fetch the whole bean.
Frank Sommers: Let's shift gears and talk about your latest release. What are the new features in RIFE 1.5?
Geert Bevin: I mentioned declarations earlier, and in 1.5 we support annotations on the controllers, or what are called elements in RIFE. Some of the things you have to declare are the data inputs from controllers, the data outputs, the URL, and the fact that data submission occurs, as from a form.
In RIFE 1.5, you can declare those as annotations on methods in your controllers. That makes it a lot easier to work with those elements, and it looks very similar to what you see in JBoss Seam. You declare what methods are present in the state management aspect of your application, and what methods respond to data submissions. Those are neatly separated as individual methods, making it very easy to read the code.
That's also an example that declarations don't have to be specified in an XML file. A lot of people today are allergic to XML. Every declaration and configuration in RIFE can be specified in plain Java. It's not just a matter of setters and getters, leaving you with having to invoke many calls on the same object instance. Instead, we actually wrote out fluent interfaces that allow you to chain those calls. It looks very similar to a nested structure you would have in XML, except that it's in Java.
Another new feature is complete bijection: injection and outjection support for setters and getters on the controllers. If you use an annotation on the setter, indicating that that is a data input, RIFE will take care of injecting data in that setter. The other way around, if you declare a getter method as a data output, the framework will obtain the data that way when it needs it. It's similar to what Seam does.
Frank Sommers: I know you did a lot of new work on continuations. What are continuations, and in what situation do they help the enterprise developer?
Geert Bevin: An easy example would be to go back a long time, to the early days of programming when people were writing simple DOS programs. That was a very easy time. The only thing you had to do when you required some user input was to use something like readline(): the prompt would just wait for someone to enter some text, and as soon as they pressed Enter, the program would continue. When you needed some other input from the user, you'd use readline() again, and the program would again pause for user input. It's a very simple way of working. You don't have to be concerned about multithreading, or multiple users, or how the state goes from one thread to another. It's very intuitive because it has a linear execution model. People have been able to do very complex applications with that model very quickly, because they didn't have to think about all the difficult things.
Continuations bring that to Web applications. You can look at a Web page as the output from a terminal. When you use continuations, you create a one-to-one conversation between the user and an instance of your application. When the application needs some input from the user, it provides an output to give the user a context in which to provide that input, which is typically an HTML page. Then the execution of the application on the server pauses. When the user submits the data, typically from a form, as the data arrives back at the server, the execution continues exactly where it left off, with the same local variable state. The input the user provided is injected, and you obtain it as though it were the return from a method call.
Frank Sommers: How would you contrast that with the REST approach, where the server doesn't have a lot of state?
Geert Bevin: It's totally the opposite. But I think both are important. Besides continuations, for most of the other things in RIFE we advocate the REST style. Continuations are extremely handy in the difficult situation of a multipage transactional process that is initiated by the user and has no direct access to intermediate steps.
Without continuations, you would have to populate the session with a lot of state identifiers to indicate what step in the process you are at, and what steps are possible. And then you would either have huge if-then-else statements to check where you are and pull in the state again, or you would have to code the individual actions to transfer the state from one location to another. And you also have to make sure that if the back button is pressed, you go back to the right location. If you have a complex check-out process, for example, that takes quite a while to get right, and is extremely heavy to create.
With a DOS program, that would be quite simple because you would know what input you needed, and if the user hasn't provided that data, you'd ask them for it, branching out as necessary, in a loop. Continuations allow you to do that in pure Java by not leaving the code at all. You don't have to externalize the logic flows.
On rifers.org, we have an example application of a multipage process. In that example, you can choose how you want an order to be shipped on the first page. On the next page, you can select a type of credit card. If you decided on the second page that you really wanted a different shipping method, you can click on the back button. The data from that previous step is still there, so you can pick a different shipping method, and then click next again. But the data from that second step is still there, too. Then you can again click on the back button and follow another path. And it will just work because it knows where you were. This is all done through continuations. If you look at the source, it's just a bunch of while() loops until certain validations assert as being valid, based on user input. The loops pause for user input, and go to the next step. And as you press the back button in your browser, it can jump back to the previous location.
Your back button is automatically handled, because each time you advance, you create a new continuation. When people go back, they can just step back and take another path, and it just works. So it's basically taking a snapshot of each step. As soon as such a multi-page input is done, you save that state, and invalidate all the continuation steps. That way, you don't have a multi-submit problem, because you invalidated the continuation steps.
In RIFE 1.5, we added step-back continuations, allowing you to jump back to a previous continuation. Coding that without continuations would be quite complex: A partial form had been submitted in the second step, validation did not kick in because in order to validate, the other fields are also required, and then we go back to this first step, and still have to remember the partial data provided in the second step. With step-back-continuations, you just detect that the back button was pressed, simply step back, and that's it.
Frank Sommers: Aren't all those continuation snapshots a resource hog on the server?
Geert Bevin: Some people think so, because you're capturing the state and cloning that state at each step. In practice, it turns out to be extremely light, because most Web applications don't have that much local state. Often, it's just a couple of variables. However, should the state be too large for cloning, then you can set a configuration parameter to disable this feature. There will then only be one instance of the state for each continuation conversation. Of course, the back button will then not revert back to the previous state. In some use cases, such as a check out process, that may just be what you want.
Frank Sommers: In addition to multi-step form input, in what other situations are continuations useful?
Geert Bevin: People have also been using continuations for event-based systems. Suppose you have an events flow declaration that takes several steps chained together. When a certain event happens, an application has to perform an action.
What you'd typically do is poll for state: You would have some kind of sleep time, and then poll to see what the state is, and if the state is not what you want, you just wait a little while, and when the required state is detected, you take the correct step.
Continuations turn that problem around. If you're at a step that requires additional information to continue, you can capture a continuation and stop the execution completely. That continuation becomes a dead object—it doesn't do anything any more. That dead object is then stored, and somewhere in an event handler you register events as being related to that object. When an event occurs, you look up all the continuations that relate to that event, and then start those continuations up again. Instead of polling, you have a very low-overhead system. We've had reports from people that the performance of their applications improved dramatically this way.
Because continuations are generally useful, we've been working on a RIFE subproject for a while with Patrick Lightbody from WebWork. The plan is by the end of the year to extract all the continuation functionality from the RIFE framework, put that into an external project, and to get a JSR going for that. We also plan to apply that project to Struts Action Framework 2, too.
Resources
RIFERS.org
http://www.rifers.org
Talk back!
Have an opinion? Readers have already posted 21 comments about this article. Why not add yours?
About the author
Frank Sommers is an Artima senior editor.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)